Como sabemos, o algoritmo de Aprendizado de Máquina Supervisionado pode ser amplamente classificado em Algoritmos de Regressão e Classificação. Nos algoritmos de regressão, previmos a saída para valores contínuos, mas para prever os valores categóricos, precisamos de algoritmos de classificação.
Qual é o algoritmo de classificação?
O algoritmo de classificação é uma técnica de aprendizagem supervisionada usada para identificar a categoria de novas observações com base em dados de treinamento. Na Classificação, um programa aprende com um determinado conjunto de dados ou observações e, em seguida, classifica a nova observação em várias classes ou grupos. Como, Sim ou Não, 0 ou 1, Spam ou Não Spam, gato ou cachorro, etc. As classes podem ser chamadas como alvos/rótulos ou categorias.
substitua tudo
Ao contrário da regressão, a variável de saída da Classificação é uma categoria, não um valor, como 'Verde ou Azul', 'fruta ou animal', etc. Como o algoritmo de Classificação é uma técnica de aprendizagem supervisionada, portanto, são necessários dados de entrada rotulados, que significa que contém entrada com a saída correspondente.
No algoritmo de classificação, uma função de saída discreta (y) é mapeada para uma variável de entrada (x).
y=f(x), where y = categorical output
O melhor exemplo de algoritmo de classificação de ML é Detector de spam de e-mail .
O principal objetivo do algoritmo de classificação é identificar a categoria de um determinado conjunto de dados, e esses algoritmos são usados principalmente para prever a saída dos dados categóricos.
Os algoritmos de classificação podem ser melhor compreendidos usando o diagrama abaixo. No diagrama abaixo, existem duas classes, classe A e classe B. Essas classes possuem recursos semelhantes entre si e diferentes de outras classes.
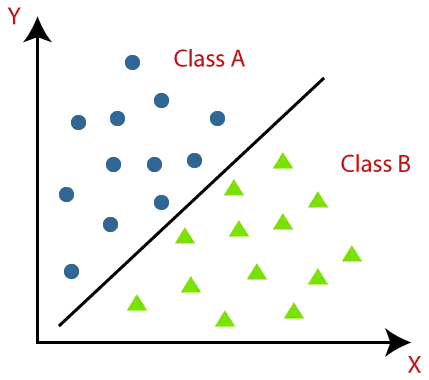
O algoritmo que implementa a classificação em um conjunto de dados é conhecido como classificador. Existem dois tipos de classificações:
Exemplos: SIM ou NÃO, MASCULINO ou FEMININO, SPAM ou NÃO SPAM, GATO ou CÃO, etc.
Exemplo: Classificações dos tipos de culturas, Classificação dos tipos de música.
Alunos em problemas de classificação:
Nos problemas de classificação, existem dois tipos de alunos:
Exemplo: Algoritmo K-NN, raciocínio baseado em casos
Tipos de algoritmos de classificação de ML:
Os algoritmos de classificação podem ser divididos principalmente em duas categorias:
- Regressão Logística
- Máquinas de vetores de suporte
- K-vizinhos mais próximos
- Núcleo SVM
- Na�ve Bayes
- Classificação da árvore de decisão
- Classificação Florestal Aleatória
Nota: Aprenderemos os algoritmos acima em capítulos posteriores.
Avaliando um modelo de classificação:
Uma vez concluído nosso modelo, é necessário avaliar seu desempenho; ou é um modelo de classificação ou regressão. Portanto, para avaliar um modelo de Classificação, temos as seguintes formas:
1. Perda de log ou perda de entropia cruzada:
- É utilizado para avaliar o desempenho de um classificador, cuja saída é um valor de probabilidade entre 0 e 1.
- Para um bom modelo de classificação binária, o valor da perda de log deve estar próximo de 0.
- O valor da perda logarítmica aumenta se o valor previsto se desviar do valor real.
- A menor perda logarítmica representa a maior precisão do modelo.
- Para classificação binária, a entropia cruzada pode ser calculada como:
?(ylog(p)+(1?y)log(1?p))
Onde y = produção real, p = produção prevista.
atalhos de teclado linux
2. Matriz de confusão:
- A matriz de confusão nos fornece uma matriz/tabela como saída e descreve o desempenho do modelo.
- Também é conhecida como matriz de erro.
- A matriz consiste no resultado das previsões de forma resumida, que possui um número total de previsões corretas e incorretas. A matriz se parece com a tabela abaixo:
| Positivo Real | Negativo real | |
|---|---|---|
| Previsto Positivo | Verdadeiro Positivo | Falso positivo |
| Negativo previsto | Falso negativo | Verdadeiro negativo |

3. Curva AUC-ROC:
- Curva ROC significa Curva de características operacionais do receptor e AUC significa Área sob a curva .
- É um gráfico que mostra o desempenho do modelo de classificação em diferentes limites.
- Para visualizar o desempenho do modelo de classificação multiclasse, utilizamos a Curva AUC-ROC.
- A curva ROC é traçada com TPR e FPR, onde TPR (Taxa de Positivo Verdadeiro) no eixo Y e FPR (Taxa de Falso Positivo) no eixo X.
Casos de uso de algoritmos de classificação
Algoritmos de classificação podem ser usados em diferentes lugares. Abaixo estão alguns casos de uso populares de algoritmos de classificação:
- Detecção de spam de e-mail
- Reconhecimento de fala
- Identificações de células tumorais cancerígenas.
- Classificação de Drogas
- Identificação Biométrica, etc.