A arquitetura a seguir explica o fluxo de envio de consulta ao Hive.
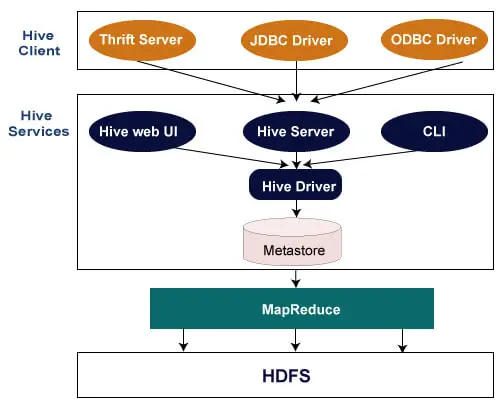
Cliente Hive
O Hive permite escrever aplicativos em várias linguagens, incluindo Java, Python e C++. Suporta diferentes tipos de clientes, como: -
- Thrift Server - É uma plataforma de provedor de serviços multilíngue que atende às solicitações de todas as linguagens de programação que suportam Thrift.
- Driver JDBC - É usado para estabelecer uma conexão entre hive e aplicativos Java. O Driver JDBC está presente na classe org.apache.hadoop.hive.jdbc.HiveDriver.
- Driver ODBC - Permite que aplicativos que suportam o protocolo ODBC se conectem ao Hive.
Serviços de colmeia
A seguir estão os serviços prestados pela Hive: -
- Hive CLI - O Hive CLI (Command Line Interface) é um shell onde podemos executar consultas e comandos do Hive.
- Hive Web User Interface - A Hive Web UI é apenas uma alternativa ao Hive CLI. Ele fornece uma GUI baseada na web para executar consultas e comandos do Hive.
- Hive MetaStore - É um repositório central que armazena todas as informações de estrutura de diversas tabelas e partições do warehouse. Também inclui metadados de coluna e informações de seu tipo, os serializadores e desserializadores usados para ler e gravar dados e os arquivos HDFS correspondentes onde os dados são armazenados.
- Servidor Hive - É conhecido como Servidor Apache Thrift. Ele aceita a solicitação de diferentes clientes e a fornece ao Hive Driver.
- Hive Driver - Ele recebe consultas de diferentes fontes, como UI da web, CLI, Thrift e driver JDBC/ODBC. Ele transfere as consultas para o compilador.
- Compilador Hive - O objetivo do compilador é analisar a consulta e realizar análise semântica nos diferentes blocos e expressões de consulta. Ele converte instruções HiveQL em trabalhos MapReduce.
- Hive Execution Engine - Optimizer gera o plano lógico na forma de DAG de tarefas de redução de mapa e tarefas HDFS. No final, o mecanismo de execução executa as tarefas recebidas na ordem de suas dependências.