Pandas
Pandas é uma biblioteca embutida em Python que é usada para trabalhar com dados relacionais na linguagem de programação Python. Possui diversas funções e estruturas de dados que auxiliam nas operações de dados relacionais.
Se os dados são armazenados na forma de linhas e colunas ou dados bidimensionais, geralmente são chamados de dataframes no pandas.
Se tivermos dois dataframes, então com a ajuda do pandas podemos combiná-los ou mesclá-los em um único dataframe. Pandas fornece a lógica definida para combinar os dados de dois dataframes diferentes, bem como a lógica para compará-los.
1. Usando a função concat()
Em python, podemos concatenar os dois dataframes com a ajuda da função concat() do Pandas. Podemos concatenar os dados em linhas ou colunas. Esta função mescla os dados de um eixo (linha ou coluna) e executa a lógica definida em outro eixo (outro índice).
Exemplo:
import pandas as pd from IPython.display import display # First DataFrame dataFrame1 = pd.DataFrame({'id': ['A1', 'A2', 'A3', 'A4'], 'Name': ['ABC', 'PQR', 'DEF', 'GHI'], 'Marks':[65,69,96,89]}) # Second DataFrame dataFrame2 = pd.DataFrame({'id': ['B1', 'B2', 'B3', 'B4'], 'Name': ['XYZ', 'TUV', 'MNO', 'JKL'], 'Marks':[56,96,69,98]}) frames = [dataFrame1, dataFrame2] result = pd.concat(frames) display(result) Saída:
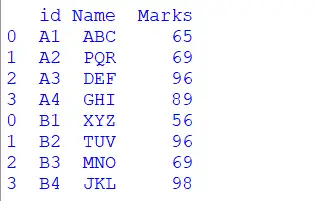
Explicação:
No código acima, primeiro importamos a biblioteca Pandas no arquivo. Em seguida, criamos os dois dataframes onde cada dataframe contém três colunas e quatro linhas. Em seguida, usamos a função concat, que concatena esses dois dataframes linha a linha, e com a função display, imprimimos isso na tela.
2. Usando junções em pandas
Compreendemos o conceito de junções no banco de dados onde unimos as duas tabelas com base em algum atributo comum. O mesmo método é aplicável na concatenação de dataframes. No método concat() simples, mesclamos todas as linhas umas nas outras e criamos o novo dataframe. No join, definimos qual tipo de join queremos realizar na tabela, se é um inner join ou um outer join. Qualquer tipo de junção, seja junção interna (interseção) ou junção externa (união), será definida no atributo de junção.
Exemplo:
converter char para int java
import pandas as pd from IPython.display import display dataFrame1 = pd.DataFrame({'id': ['A1', 'A2', 'A3', 'A4'], 'Name': ['ABC', 'PQR', 'TUV', 'JKL']}) dataFrame2 = pd.DataFrame({'City': ['NOIDA', 'JAIPUR', 'MANALI', 'DELHI'], 'Age': ['11', '10', '12', '17']}) # the default behaviour is join='outer' # inner join result = pd.concat([dataFrame1, dataFrame2], axis=1, join='inner') display(result) Saída:

Explicação:
No código acima, temos dois daraframes que contêm duas colunas e quatro linhas. Ambos os dataframes têm nomes de colunas diferentes e, na função concat(), usamos a junção interna, que ocupa a parte da interseção.
No atributo axis, inicializamos o valor um, então obtivemos todos os dados.
Exemplo:
import pandas as pd from IPython.display import display dataFrame1 = pd.DataFrame({'id': ['A1', 'A2', 'A3', 'A4'], 'Name': ['ABC', 'PQR', 'TUV', 'JKL']}) dataFrame2 = pd.DataFrame({'id': ['A1', 'A2', 'A3', 'A4'],'City': ['NOIDA', 'JAIPUR', 'MANALI', 'DELHI'], 'Age': ['11', '10', '12', '17']}) # the default behaviour is join='outer' # inner join result = pd.concat([dataFrame1, dataFrame2], axis=0, join='inner') display(result) Saída:
Arquitetura de 32 bits versus 64 bits

Como não há nenhum atributo comum e a junção interna foi aplicada, obtivemos um dataframe vazio como saída. Se houver um atributo comum em ambos os dataframes:
Exemplo:
import pandas as pd from IPython.display import display dataFrame1 = pd.DataFrame({'id': ['A1', 'A2', 'A3', 'A4'], 'Name': ['ABC', 'PQR', 'TUV', 'JKL']}) dataFrame2 = pd.DataFrame({'id': ['B1', 'B2', 'B3', 'B4'], 'City': ['NOIDA', 'JAIPUR', 'MANALI', 'DELHI'], 'Age': ['11', '10', '12', '17']}) # the default behaviour is join='outer' # inner join result = pd.concat([dataFrame1, dataFrame2], axis=0, join='inner') display(result) Saída:

Explicação:
No código acima, temos um atributo, 'id', que é comum, portanto o dataframe é criado com base apenas em atributos comuns.
3. Usando o método anexar()
Em vez do método concat(), podemos usar o método append(). Este método append() é aplicado a um dos dataframes.
Exemplo:
import pandas as pd from IPython.display import display # First DataFrame dataFrame1 = pd.DataFrame({'id': ['A1', 'A2', 'A3', 'A4'], 'City': ['JAIPUR', 'MANALI', 'NOIDA', 'LUCKNOW']}) # Second DataFrame dataFrame2 = pd.DataFrame({'id': ['B1', 'B2', 'B3', 'B4'], 'City': ['MUMBAI', 'UDAIPUR', 'RISHIKESH', 'KASHMIR']}) # append method result = dataFrame1.append(dataFrame2) display(result) Saída:

Explicação:
No código acima, mesclamos dois dataframes usando o método append.