Na seção anterior, fizemos uma breve introdução sobre o Apache Kafka, o sistema de mensagens, bem como o processo de streaming. Aqui discutiremos os conceitos básicos e o papel de Kafka.
Tópicos
Geralmente, um tópico refere-se a um título específico ou a um nome dado a algumas ideias específicas inter-relacionadas. Em Kafka, a palavra tópico refere-se a uma categoria ou nome comum usado para armazenar e publicar um determinado fluxo de dados. Basicamente, os tópicos do Kafka são semelhantes às tabelas do banco de dados, mas não contêm todas as restrições. No Kafka, podemos criar n números de tópicos que quisermos. É identificado pelo seu nome, que depende da escolha do usuário. Um produtor publica dados nos tópicos e um consumidor lê esses dados do tópico assinando-o.
Partições
Um tópico é dividido em várias partes que são conhecidas como partições do tópico. Essas partições são separadas em uma ordem. O conteúdo dos dados é armazenado nas partições do tópico. Portanto, ao criar um tópico, precisamos especificar o número de partições (o número é arbitrário e pode ser alterado posteriormente). Cada mensagem é armazenada em partições com um ID incremental conhecido como valor de deslocamento. A ordem do valor de deslocamento é garantido apenas dentro da partição e não através da partição. Os deslocamentos para uma partição são infinitos.
Observação:Os dados, uma vez gravados em uma partição, nunca podem ser alterados. É imutável. O valor do deslocamento sempre permanece em estado incremental, nunca volta para um espaço vazio. Além disso, os dados são mantidos em uma partição apenas por tempo limitado.
Vejamos um exemplo para entender um tópico com suas partições.
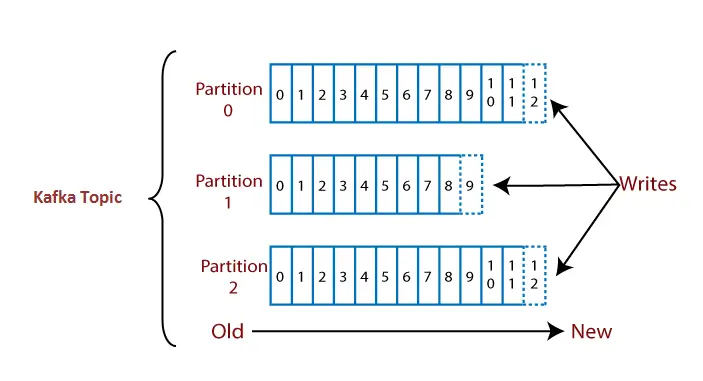
Suponha um tópico contendo três partições 0,1 e 2. Cada partição possui números de deslocamento diferentes. Os dados são distribuídos entre cada deslocamento em cada partição onde os dados no deslocamento 1 da Partição 0 não têm nenhuma relação com os dados no deslocamento 1 da Partição1. Porém, os dados no deslocamento 1 da Partição 0 estão inter-relacionados com os dados contidos no deslocamento 2 da Partição 0.
Corretores
Aí vem o papel do Apache Kafka.
Um cluster Kafka é composto por um ou mais servidores conhecidos como corretores ou corretores Kafka. Um corretor é um contêiner que contém vários tópicos com suas múltiplas partições. Os corretores no cluster são identificados apenas por um ID inteiro. Os corretores Kafka também são conhecidos como Corretores de inicialização porque a conexão com qualquer corretor significa conexão com todo o cluster. Embora um corretor não contenha dados completos, cada corretor no cluster conhece todos os outros corretores, partições e também tópicos.

É assim que um corretor se parece na figura contendo um tópico com n número de partições.
Exemplo: Corretores e Tópicos
Suponha que um cluster Kafka consista em três corretores, nomeadamente Corretor 1, Corretor 2 e Corretor 3.

Cada corretora contém um tópico, nomeadamente Tópico-x com três partições 0,1 e 2. Lembre-se, todas as partições não pertencem a apenas um corretor, é sempre distribuída entre cada corretor (depende da quantidade). O Broker 1 e o Broker 2 contêm outro tópico-y com duas partições 0 e 1. Assim, o Broker 3 não contém nenhum dado do Tópico-y. Conclui-se também que nunca existe relação entre o número do corretor e o número da partição.