O comando uniq do Linux é usado para remover todas as linhas repetidas de um arquivo. Além disso, pode ser usado para exibir a contagem de qualquer palavra, apenas linhas repetidas, ignorar caracteres e comparar campos específicos. É um dos comandos mais usados em o Linux sistema. Muitas vezes é usado com comando de classificação porque compara caracteres adjacentes. Ele descarta todas as linhas idênticas e grava a saída.
Sintaxe:
uniq [OPTION]... [INPUT [OUTPUT]]
Opções:
Algumas opções úteis de linha de comando do comando uniq são as seguintes:
-c, --contar: ele prefixa as linhas pelo número de ocorrências.
exemplo de mapa java
-d, --repetido: é usado para imprimir linhas duplicadas, uma para cada grupo.
-D: É usado para imprimir todas as linhas duplicadas.
--all-repetido[=MÉTODO]: É bastante semelhante à opção '-D', a diferença entre as duas opções é que permite a separação dos grupos com uma linha vazia.
-f, --skip-campos=N: É usado para evitar comparação dos primeiros N campos.
--grupo[=MÉTODO]: É utilizado para exibir todos os itens e separa os grupos com uma linha vazia.
-i, --ignore-case: É usado para ignorar as diferenças durante a comparação.
-s, --skip-chars=N: É usado para evitar a comparação dos primeiros N caracteres.
char para string java
-você, --único: é usado para imprimir linhas exclusivas.
-z, --terminado em zero: É usado para que o delimitador de linha seja NUL e não o modo de nova linha.
-w, --check-chars=N: É usado para comparar no máximo N caracteres em linhas.
--ajuda: É usado para exibir documentação de ajuda.
Fila de prioridade
--versão: É usado para exibir as informações da versão.
Exemplos de comando uniq
Vejamos os seguintes exemplos do comando uniq:
- Remover linhas repetidas
- contar o número de ocorrências de uma palavra
- Exibir as linhas repetidas
- Exibir as linhas exclusivas
- Ignorar caracteres em comparação
- Ignorar campos em comparação
Remover linhas repetidas
Para remover linhas repetidas de um arquivo, execute o comando uniq básico da seguinte forma:
sort dupli.txt | uniq
O comando acima removerá as linhas duplicadas do arquivo ‘dupli.txt’. Considere a saída abaixo:
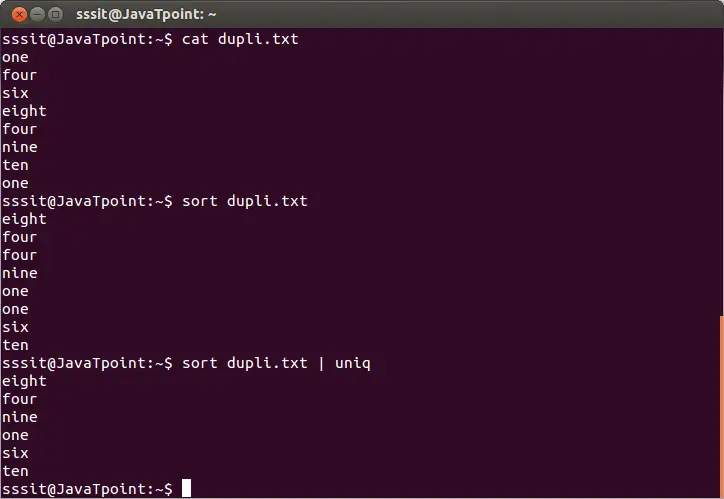
Na saída acima, as palavras repetidas são ignoradas.
Conte o número de ocorrências de uma palavra
Podemos contar o número de ocorrências de uma palavra usando o comando uniq. A opção '-c' é usada para contar a palavra. Execute-o da seguinte forma:
raposa vs lobo
sort dupli.txt | uniq -c
O comando acima contará as palavras que vêm em 'dupli.txt'. Considere a saída abaixo:

Na saída acima, o comando 'sort dupli.txt | uniq -c' conta o número de vezes que uma palavra se repete.
Exibir as linhas repetidas
A opção '-d' é usada para exibir apenas as linhas repetidas. Ele exibirá apenas as linhas que estarão mais de uma vez em um arquivo e gravará a saída na saída padrão. Considere o comando abaixo:
sort dupli.txt | uniq -d
O comando acima exibirá apenas as linhas repetidas. Considere a saída abaixo:

Exibir as linhas exclusivas
A opção '-u' é usada para exibir apenas as linhas únicas (que não são repetidas). Ele exibirá apenas as linhas que ocorrem apenas uma vez e gravará o resultado na saída padrão. Considere o comando abaixo:
sort dupli.txt | uniq -u
O comando acima exibirá apenas as linhas exclusivas do arquivo ‘dupli.txt’. Considere a saída abaixo:
diferença entre empresa e empresa

Ignorar caracteres em comparação
A opção '-s' é usada para ignorar os caracteres na comparação. Ele irá ignorar o número especificado de caracteres e exibir o resultado na saída padrão. Considere o comando abaixo:
sort dupli.txt | uniq -s 2
O comando acima irá ignorar os dois primeiros caracteres em comparação com o arquivo 'dupli.txt'. Considere a saída abaixo:

Ignorar campos em comparação
A opção '-f' é usada para ignorar os campos. Considere o comando abaixo:
uniq -f 2 dupli2.txt
O comando acima não comparará os dois primeiros campos do arquivo 'dupli2.txt'. Considere a saída abaixo:

Na saída acima, os dois primeiros campos são ignorados e o restante de todos os campos é comparado a partir do arquivo 'dupli2.txt'.