Em Java, gerenciamento de memória é o processo de alocação e desalocação de objetos, denominado gerenciamento de memória. Java faz o gerenciamento de memória automaticamente. Java usa um sistema automático de gerenciamento de memória chamado coletor de lixo . Assim, não somos obrigados a implementar lógica de gerenciamento de memória em nossa aplicação. O gerenciamento de memória Java se divide em duas partes principais:
Estrutura de memória JVM
A JVM cria várias áreas de dados de tempo de execução em um heap. Estas áreas são utilizadas durante a execução do programa. As áreas de memória são destruídas quando a JVM é encerrada, enquanto as áreas de dados são destruídas quando o thread é encerrado.
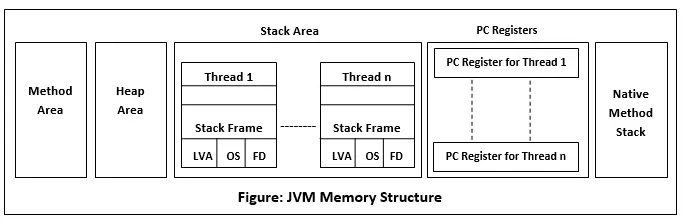
Área de Método
A Área de Método faz parte da memória heap que é compartilhada entre todos os threads. Ele é criado quando a JVM é inicializada. É usado para armazenar estrutura de classe, nome de superclasse, nome de interface e construtores. A JVM armazena os seguintes tipos de informações na área de métodos:
- Um nome totalmente qualificado de um tipo (ex: String)
- Os modificadores do tipo
- Nome direto da superclasse do tipo
- Uma lista estruturada de nomes totalmente qualificados de superinterfaces.
Área de pilha
Heap armazena os objetos reais. Ele é criado quando a JVM é inicializada. O usuário pode controlar o heap, se necessário. Pode ser de tamanho fixo ou dinâmico. Quando você usa uma nova palavra-chave, a JVM cria uma instância para o objeto em um heap. Enquanto a referência desse objeto é armazenada na pilha. Existe apenas um heap para cada processo JVM em execução. Quando a pilha fica cheia, o lixo é coletado. Por exemplo:
StringBuilder sb= new StringBuilder();
A instrução acima cria um objeto da classe StringBuilder. O objeto é alocado para o heap e a referência sb é alocada para a pilha. O heap é dividido nas seguintes partes:
algoritmo de Kruskals
- Geração jovem
- Espaço do sobrevivente
- Velha geração
- Geração permanente
- Cache de código
Tipo de referência
Existem quatro tipos de referências: Forte , Fraco , Macio , e Referência fantasma . A diferença entre os tipos de referências é que os objetos no heap aos quais se referem são elegíveis para coleta de lixo sob diferentes critérios.
Referência forte: É muito simples porque o utilizamos na nossa programação diária. Qualquer objeto que tenha uma referência forte anexada não é elegível para coleta de lixo. Podemos criar uma referência forte usando a seguinte declaração:
StringBuilder sb= new StringBuilder();
Referência Fraca: Ele não sobrevive após o próximo processo de coleta de lixo. Se não tivermos certeza de quando os dados serão solicitados novamente. Nesta condição, podemos criar uma referência fraca a ele. Caso o coletor de lixo processe, ele destrói o objeto. Quando tentamos recuperar esse objeto novamente, obtemos um valor nulo. É definido em java.lang.ref.WeakReference aula. Podemos criar uma referência fraca usando a seguinte declaração:
WeakReference reference = new WeakReference(new StringBuilder());
Referência suave: Ele é coletado quando o aplicativo está com pouca memória. O coletor de lixo não coleta os objetos facilmente acessíveis. Todos os objetos com referência suave são coletados antes de lançar um OutOfMemoryError. Podemos criar uma referência suave usando a seguinte instrução:
SoftReference reference = new SoftReference(new StringBuilder());
Referência Fantasma: Está disponível em java.lang.ref pacote. É definido em java.lang.ref.PhantomReference aula. O objeto que possui apenas uma referência fantasma apontando para ele pode ser coletado sempre que o coletor de lixo desejar coletar. Podemos criar uma referência fantasma usando a seguinte instrução:
PhantomReference reference = new PhantomReference(new StringBuilder());
Área de pilha
A área de pilha é gerada quando um thread é criado. Pode ser de tamanho fixo ou dinâmico. A memória da pilha é alocada por thread. É usado para armazenar dados e resultados parciais. Ele contém referências a objetos heap. Ele também contém o valor em si, em vez de uma referência a um objeto do heap. As variáveis armazenadas na pilha possuem certa visibilidade, chamada escopo.
Quadro de pilha: Stack frame é uma estrutura de dados que contém os dados do thread. Os dados do thread representam o estado do thread no método atual.
- É usado para armazenar resultados e dados parciais. Também realiza vinculação dinâmica, retorno de valores por métodos e despacho de exceções.
- Quando um método é invocado, um novo quadro é criado. Ele destrói o quadro quando a invocação do método é concluída.
- Cada quadro contém sua própria Matriz de Variável Local (LVA), Pilha de Operandos (OS) e Dados de Quadro (FD).
- Os tamanhos de LVA, OS e FD determinados em tempo de compilação.
- Apenas um quadro (o quadro para execução do método) está ativo em qualquer ponto de um determinado thread de controle. Esse quadro é chamado de quadro atual e seu método é conhecido como método atual. A classe do método é chamada de classe atual.
- O quadro interrompe o método atual, se seu método invocar outro método ou se o método for concluído.
- O quadro criado por um thread é local para esse thread e não pode ser referenciado por nenhum outro thread.
Pilha de métodos nativos
Também é conhecido como pilha C. É uma pilha para código nativo escrito em uma linguagem diferente de Java. Java Native Interface (JNI) chama a pilha nativa. O desempenho da pilha nativa depende do sistema operacional.
Registros de PC
Cada thread possui um registro Program Counter (PC) associado a ele. O registro do PC armazena o endereço de retorno ou um ponteiro nativo. Ele também contém o endereço das instruções JVM que estão sendo executadas atualmente.
Trabalho do coletor de lixo
Visão geral do coletor de lixo
Quando um programa é executado em Java, ele usa memória de diferentes maneiras. O heap é uma parte da memória onde vivem os objetos. É a única parte da memória envolvida no processo de coleta de lixo. Também é conhecido como pilha de lixo colecionável. Toda a coleta de lixo garante que o heap tenha o máximo de espaço livre possível. A função do coletor de lixo é localizar e excluir os objetos que não podem ser alcançados.
Alocação de objetos
Quando um objeto é alocado, a JVM JRockit verifica o tamanho do objeto. Ele distingue entre objetos pequenos e grandes. O tamanho pequeno e grande depende da versão da JVM, do tamanho do heap, da estratégia de coleta de lixo e da plataforma usada. O tamanho de um objeto geralmente está entre 2 e 128 KB.
Os pequenos objetos são armazenados na Thread Local Area (TLA), que é um pedaço livre do heap. O TLA não sincroniza com outros threads. Quando o TLA fica cheio, ele solicita um novo TLA.
Por outro lado, objetos grandes que não cabem no TLA são alocados diretamente no heap. Se um thread estiver usando o espaço novo, ele será armazenado diretamente no espaço antigo. O objeto grande requer mais sincronização entre os threads.
O que o Java Garbage Collector?
JVM controla o coletor de lixo. A JVM decide quando realizar a coleta de lixo. Também podemos solicitar à JVM que execute o coletor de lixo. Mas não há garantia, sob quaisquer condições, de que a JVM cumprirá. A JVM executa o coletor de lixo se detectar que a memória está acabando. Quando o programa Java solicita o coletor de lixo, a JVM geralmente concede a solicitação em pouco tempo. Não garante que as solicitações sejam aceitas.
O ponto a entender é que ' quando um objeto se torna elegível para coleta de lixo? '
Todo programa Java possui mais de um thread. Cada thread tem sua pilha de execução. Existe um thread para executar no programa Java que é um método main(). Agora podemos dizer que um objeto é elegível para coleta de lixo quando nenhum thread ativo pode acessá-lo. O coletor de lixo considera esse objeto elegível para exclusão. Se um programa possui uma variável de referência que se refere a um objeto, essa variável de referência disponível para o thread ativo, esse objeto é chamado alcançável .
Aqui surge uma questão que ' Um aplicativo Java pode ficar sem memória? '
A resposta é sim. O sistema de coleta de lixo tenta remover objetos da memória quando eles não estão em uso. Porém, se você estiver mantendo muitos objetos ativos, a coleta de lixo não garante que haja memória suficiente. Somente a memória disponível será gerenciada de forma eficaz.
Tipos de coleta de lixo
Existem cinco tipos de coleta de lixo:
Algoritmo de marcação e varredura
JRockit JVM usa o algoritmo de marcação e varredura para realizar a coleta de lixo. Ele contém duas fases, a fase de marcação e a fase de varredura.
Fase de Marcação: Objetos acessíveis a partir de threads, identificadores nativos e outras fontes raiz de GC são marcados como ativos. Cada árvore de objetos possui mais de um objeto raiz. A raiz do GC está sempre acessível. Portanto, qualquer objeto que tenha uma raiz de coleta de lixo em sua raiz. Identifica e marca todos os objetos que estão em uso, podendo o restante ser considerado lixo.

Fase de varredura: Nesta fase, o heap é percorrido para encontrar a lacuna entre os objetos vivos. Essas lacunas são registradas na lista livre e ficam disponíveis para alocação de novos objetos.
Existem duas versões melhoradas de marcação e varredura:
Marcação e varredura simultâneas
Ele permite que os threads continuem em execução durante grande parte da coleta de lixo. Existem os seguintes tipos de marcação:
Marcação e varredura paralela
Ele utiliza toda a CPU disponível no sistema para realizar a coleta de lixo o mais rápido possível. Também é chamado de coletor de lixo paralelo. Threads não são executados quando a coleta de lixo paralela é executada.
Prós de marcar e varrer
- É um processo recorrente.
- É um loop infinito.
- Nenhuma sobrecarga adicional é permitida durante a execução de um algoritmo.
Contras de marcar e varrer
- Ele interrompe a execução normal do programa enquanto o algoritmo de coleta de lixo é executado.
- Ele é executado várias vezes em um programa.