Algoritmos de regressão e classificação são algoritmos de aprendizagem supervisionada. Ambos os algoritmos são usados para previsão em aprendizado de máquina e funcionam com conjuntos de dados rotulados. Mas a diferença entre ambos é como eles são usados para diferentes problemas de aprendizado de máquina.
A principal diferença entre algoritmos de regressão e classificação que os algoritmos de regressão são usados para prever o contínuo valores como preço, salário, idade, etc. e algoritmos de classificação são usados para prever/classificar os valores discretos como Masculino ou Feminino, Verdadeiro ou Falso, Spam ou Não Spam, etc.
Considere o diagrama abaixo:
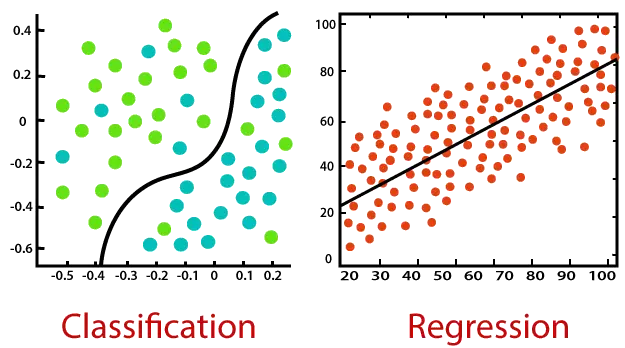
Classificação:
Classificação é um processo de encontrar uma função que ajuda a dividir o conjunto de dados em classes com base em diferentes parâmetros. Na Classificação, um programa de computador é treinado no conjunto de dados de treinamento e, com base nesse treinamento, categoriza os dados em diferentes classes.
A tarefa do algoritmo de classificação é encontrar a função de mapeamento para mapear a entrada (x) para a saída discreta (y).
Exemplo: O melhor exemplo para entender o problema de classificação é a detecção de spam por e-mail. O modelo é treinado com base em milhões de emails em diversos parâmetros e, sempre que recebe um novo email, identifica se o email é spam ou não. Se o e-mail for spam, ele será movido para a pasta Spam.
datilografado cada
Tipos de algoritmos de classificação de ML:
Os algoritmos de classificação podem ser divididos nos seguintes tipos:
- Regressão Logística
- K-vizinhos mais próximos
- Máquinas de vetores de suporte
- Núcleo SVM
- Na�ve Bayes
- Classificação da árvore de decisão
- Classificação Florestal Aleatória
Regressão:
A regressão é um processo de encontrar correlações entre variáveis dependentes e independentes. Ajuda na previsão de variáveis contínuas, como a previsão de Tendências de mercado , previsão de preços de casas, etc.
A tarefa do algoritmo de regressão é encontrar a função de mapeamento para mapear a variável de entrada (x) para a variável de saída contínua (y).
Exemplo: Suponha que queiramos fazer uma previsão do tempo, então para isso utilizaremos o algoritmo de Regressão. Na previsão do tempo, o modelo é treinado com base nos dados anteriores e, uma vez concluído o treinamento, ele pode prever facilmente o clima para os dias futuros.
Tipos de algoritmo de regressão:
identificadores válidos em java
- Regressão Linear Simples
- Regressão linear múltipla
- Regressão Polinomial
- Regressão de vetores de suporte
- Regressão da árvore de decisão
- Regressão Florestal Aleatória
Diferença entre regressão e classificação
| Algoritmo de regressão | Algoritmo de Classificação |
|---|---|
| Na Regressão, a variável de saída deve ser de natureza contínua ou de valor real. | Em Classificação, a variável de saída deve ser um valor discreto. |
| A tarefa do algoritmo de regressão é mapear o valor de entrada (x) com a variável de saída contínua (y). | A tarefa do algoritmo de classificação é mapear o valor de entrada (x) com a variável de saída discreta (y). |
| Algoritmos de regressão são usados com dados contínuos. | Algoritmos de classificação são usados com dados discretos. |
| Na regressão, tentamos encontrar a linha de melhor ajuste, que pode prever a saída com mais precisão. | Em Classificação, tentamos encontrar o limite de decisão, que pode dividir o conjunto de dados em diferentes classes. |
| Algoritmos de regressão podem ser usados para resolver problemas de regressão, como previsão do tempo, previsão de preços de casas, etc. | Algoritmos de classificação podem ser usados para resolver problemas de classificação, como identificação de e-mails de spam, reconhecimento de fala, identificação de células cancerígenas, etc. |
| O algoritmo de regressão pode ser dividido em regressão linear e não linear. | Os algoritmos de classificação podem ser divididos em Classificador Binário e Classificador Multiclasse. |