No Sistema Operacional, tínhamos que dar a entrada para a CPU, e a CPU executa as instruções e finalmente dá a saída. Mas havia um problema com essa abordagem. Numa situação normal, temos que lidar com muitos processos, e sabemos que o tempo gasto na operação de I/O é muito grande comparado ao tempo gasto pela CPU para a execução das instruções. Portanto, na abordagem antiga, um processo fornecerá a entrada com a ajuda de um dispositivo de entrada e, durante esse tempo, a CPU ficará em estado ocioso.
ano mês
Em seguida, a CPU executa a instrução e a saída é novamente fornecida a algum dispositivo de saída e, neste momento, a CPU também está em estado inativo. Após mostrar a saída, o próximo processo inicia sua execução. Então, na maioria das vezes a CPU fica ociosa, que é a pior condição que podemos ter em Sistemas Operacionais. Aqui, o conceito de Spooling entra em jogo.
O que é spool
Spooling é um processo no qual os dados são retidos temporariamente para serem usados e executados por um dispositivo, programa ou sistema. Os dados são enviados e armazenados na memória ou outro armazenamento volátil até que o programa ou computador os solicite para execução.
SPOOL é um acrônimo para operações periféricas simultâneas on-line . Geralmente, o spool é mantido na memória física do computador, nos buffers ou nas interrupções específicas do dispositivo de E/S. O spool é processado em ordem crescente, trabalhando com base em um algoritmo FIFO (primeiro a entrar, primeiro a sair).
Spooling refere-se a colocar dados de vários trabalhos de E/S em um buffer. Este buffer é uma área especial na memória ou no disco rígido que é acessível a dispositivos de E/S. Um sistema operacional realiza as seguintes atividades relacionadas ao ambiente distribuído:
- Lida com o spool de dados do dispositivo de E/S, pois os dispositivos têm taxas de acesso de dados diferentes.
- Mantém o buffer de spool, que fornece uma estação de espera onde os dados podem descansar enquanto o dispositivo mais lento os alcança.
- Mantém a computação paralela devido ao processo de spool, pois um computador pode executar E/S em ordem paralela. Torna-se possível fazer com que o computador leia dados de uma fita, grave dados em disco e grave em uma impressora de fita enquanto executa sua tarefa de computação.
Como funciona o spool no sistema operacional
Em um sistema operacional, o spool funciona nas seguintes etapas, como:
- O spooling envolve a criação de um buffer chamado SPOOL, que é usado para reter tarefas e dados até que o dispositivo no qual o SPOOL foi criado esteja pronto para usar e executar essa tarefa ou operar nos dados.
- Quando um dispositivo mais rápido envia dados para um dispositivo mais lento para realizar alguma operação, ele usa qualquer memória secundária anexada como buffer SPOOL. Esses dados são mantidos no SPOOL até que o dispositivo mais lento esteja pronto para operar com esses dados. Quando o dispositivo mais lento estiver pronto, os dados no SPOOL serão carregados na memória principal para as operações necessárias.
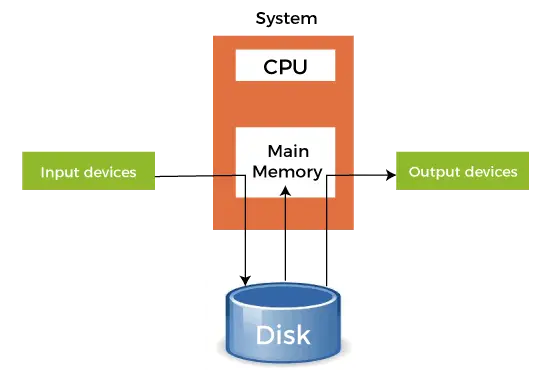
- O spooling considera toda a memória secundária como um enorme buffer que pode armazenar muitos trabalhos e dados para muitas operações. A vantagem do Spooling é que ele pode criar uma fila de trabalhos que são executados na ordem FIFO para executar os trabalhos um por um.
- Um dispositivo pode se conectar a muitos dispositivos de entrada, o que pode exigir alguma operação em seus dados. Assim, todos esses dispositivos de entrada podem colocar seus dados na memória secundária (SPOOL), que podem então ser executados um a um pelo dispositivo. Isso garantirá que a CPU não fique ociosa em nenhum momento. Portanto, podemos dizer que Spooling é uma combinação de buffer e enfileiramento.
- Depois que a CPU gera alguma saída, essa saída é primeiro salva na memória principal. Esta saída é transferida da memória principal para a memória secundária e, a partir daí, a saída é enviada para os respectivos dispositivos de saída.

Exemplo de spool
O maior exemplo de Spooling é impressão . Os documentos a serem impressos são armazenados no SPOOL e depois adicionados à fila para impressão. Durante esse tempo, muitos processos podem realizar suas operações e utilizar a CPU sem esperar enquanto a impressora executa o processo de impressão dos documentos um por um.

Muitos recursos também podem ser adicionados ao processo de impressão em spool, como definir prioridades ou notificação quando o processo de impressão for concluído ou selecionar os diferentes tipos de papel para imprimir de acordo com a escolha do usuário.
Vantagens do spool
Aqui estão as seguintes vantagens do spool em um sistema operacional, como:
- O número de dispositivos ou operações de E/S não importa. Muitos dispositivos de E/S podem trabalhar juntos simultaneamente sem qualquer interferência ou interrupção entre si.
- No spool, não há interação entre os dispositivos de E/S e a CPU. Isso significa que não há necessidade de a CPU esperar que as operações de E/S ocorram. Tais operações demoram muito para terminar a execução, então a CPU não esperará que elas terminem.
- A CPU no estado inativo não é considerada muito eficiente. A maioria dos protocolos é criada para utilizar a CPU de forma eficiente no mínimo de tempo. No spool, a CPU fica ocupada a maior parte do tempo e só vai para o estado inativo quando a fila se esgota. Assim, todas as tarefas são adicionadas à fila, e a CPU irá finalizar todas essas tarefas e então entrar no estado inativo.
- Ele permite que os aplicativos sejam executados na velocidade da CPU enquanto operam os dispositivos de E/S em suas respectivas velocidades máximas.
Desvantagens do spool
Em um sistema operacional, o spool tem as seguintes desvantagens, como:
- O spooling requer uma grande quantidade de armazenamento dependendo do número de solicitações feitas pela entrada e do número de dispositivos de entrada conectados.
- Como o SPOOL é criado no armazenamento secundário, ter muitos dispositivos de entrada funcionando simultaneamente pode ocupar muito espaço no armazenamento secundário e, assim, aumentar o tráfego em disco. Isso faz com que o disco fique cada vez mais lento à medida que o tráfego aumenta cada vez mais.
- O spooling é usado para copiar e executar dados de um dispositivo mais lento para um dispositivo mais rápido. O dispositivo mais lento cria um SPOOL para armazenar os dados a serem operados em uma fila, e a CPU trabalha nele. Esse processo por si só torna o Spooling inútil para uso em ambientes de tempo real onde precisamos de resultados em tempo real da CPU. Isso ocorre porque o dispositivo de entrada é mais lento e, portanto, produz seus dados em um ritmo mais lento, enquanto a CPU pode operar mais rapidamente, passando para o próximo processo na fila. É por isso que o resultado final ou saída é produzido posteriormente, em vez de em tempo real.
Diferença entre spool e buffer
Spooling e buffer são as duas maneiras pelas quais os subsistemas de E/S melhoram o desempenho e a eficiência do computador usando um espaço de armazenamento na memória principal ou no disco.

A diferença básica entre Spooling e Buffering é que o Spooling sobrepõe a E/S de um trabalho à execução de outro trabalho. Em comparação, o buffer sobrepõe a E/S de um trabalho com a execução do mesmo trabalho. Abaixo estão mais algumas diferenças entre Spooling e Buffering, como:
melhor automóvel do mundo
| Termos | Enrolando | Carregando |
|---|---|---|
| Definição | Spooling, um acrônimo de Simultaneous Peripheral Operation Online (SPOOL), coloca os dados em uma área de trabalho temporária para serem acessados e processados por outro programa ou recurso. | Buffering é um ato de armazenar dados temporariamente no buffer. Ajuda a combinar a velocidade do fluxo de dados entre o remetente e o destinatário. |
| Requisito de recursos | O spooling requer menos gerenciamento de recursos, pois diferentes recursos gerenciam o processo para tarefas específicas. | O buffer requer mais gerenciamento de recursos, pois o mesmo recurso gerencia o processo do mesmo trabalho dividido. |
| Implementação interna | O spool sobrepõe a entrada e a saída de um trabalho com o cálculo de outro trabalho. | O buffer sobrepõe a entrada e a saída de um trabalho com o cálculo do mesmo trabalho. |
| Eficiente | O spool é mais eficiente que o buffer. | O buffer é menos eficiente que o spool. |
| Processador | O spool também pode processar dados em locais remotos. O spooler só precisa notificar quando um processo é concluído no site remoto para colocar o próximo processo em spool no dispositivo remoto. | O buffer não oferece suporte ao processamento remoto. |
| Tamanho na memória | Ele considera o disco como um enorme spool ou buffer. | Buffer é uma área limitada na memória principal. |