A palavra-chave IDENTITY é uma propriedade do SQL Server. Quando uma coluna da tabela é definida com uma propriedade de identidade, seu valor será um valor incremental gerado automaticamente . Este valor é criado automaticamente pelo servidor. Portanto, não podemos inserir manualmente um valor em uma coluna de identidade como usuário. Portanto, se marcarmos uma coluna como identidade, o SQL Server irá preenchê-la de maneira autoincrementada.
Sintaxe
A seguir está a sintaxe para ilustrar o uso da propriedade IDENTITY no SQL Server:
IDENTITY[(seed, increment)]
Os parâmetros de sintaxe acima são explicados abaixo:
Vamos entender esse conceito por meio de um exemplo simples.
Suponha que temos um ' Estudante 'mesa, e queremos Identidade estudantil ser gerado automaticamente. Nós temos uma carteira de estudante inicial de 10 e deseja aumentá-lo em 1 a cada novo ID. Neste cenário, os seguintes valores devem ser definidos.
Semente: 10
Incremento: 1
CREATE TABLE Student ( StudentID INT IDENTITY(10, 1) PRIMARY KEY NOT NULL, )
NOTA: Somente uma coluna de identificação é permitida por tabela no SQL Server.
Exemplo de IDENTIDADE do SQL Server
Vamos entender como podemos usar a propriedade de identidade na tabela. A propriedade de identidade em uma coluna pode ser definida quando a nova tabela é criada ou após ela ter sido criada. Aqui veremos ambos os casos com exemplos.
Propriedade IDENTITY com nova tabela
A instrução a seguir criará uma nova tabela com a propriedade de identidade no banco de dados especificado:
CREATE TABLE person ( PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL, Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
A seguir, inseriremos uma nova linha nesta tabela com um SAÍDA cláusula para ver o ID da pessoa gerado automaticamente:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.PersonID VALUES('Sara Jackson', 'HR', 'Female');
A execução desta consulta exibirá a saída abaixo:
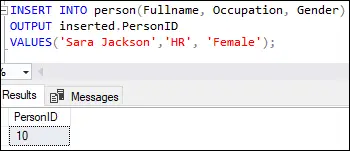
Esta saída mostra que a primeira linha foi inserida com o valor dez no ID da pessoa coluna conforme especificado na coluna de identidade de definição de tabela.
Vamos inserir outra linha no mesa de pessoa como abaixo:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.* VALUES('Mark Boucher', 'Cricketer', 'Male'), ('Josh Phillip', 'Writer', 'Male');
Esta consulta retornará a seguinte saída:

Esta saída mostra que a segunda linha foi inserida com o valor 11 e a terceira linha com o valor 12 na coluna PersonID.
Propriedade IDENTITY com tabela existente
Explicaremos esse conceito primeiro excluindo a tabela acima e criando-as sem propriedade de identidade. Execute a instrução abaixo para eliminar a tabela:
DROP TABLE person;
A seguir, criaremos uma tabela usando a consulta abaixo:
CREATE TABLE person ( Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Se quisermos adicionar uma nova coluna com a propriedade identidade em uma tabela existente, precisamos usar o comando ALTER. A consulta abaixo adicionará PersonID como uma coluna de identidade na tabela person:
ALTER TABLE person ADD PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL;
Adicionando valor explicitamente à coluna de identidade
Se adicionarmos uma nova linha à tabela acima especificando explicitamente o valor da coluna de identidade, o SQL Server gerará um erro. Veja a consulta abaixo:
INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 13);
A execução desta consulta ocorrerá através do seguinte erro:

Para inserir explicitamente o valor da coluna de identidade, precisamos primeiro definir o valor IDENTITY_INSERT ON. Em seguida, execute a operação de inserção para adicionar uma nova linha à tabela e defina o valor IDENTITY_INSERT como OFF. Veja o script de código abaixo:
SET IDENTITY_INSERT person ON /*INSERT VALUE*/ INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 14); SET IDENTITY_INSERT person OFF SELECT * FROM person;
IDENTITY_INSERT ATIVADO permite que os usuários coloquem dados em colunas de identidade, enquanto IDENTITY_INSERT DESATIVADO os impede de agregar valor a esta coluna.
A execução do script de código exibirá a saída abaixo, onde podemos ver que o PersonID com valor 14 foi inserido com sucesso.

Função IDENTIDADE
O SQL Server fornece algumas funções de identidade para trabalhar com colunas IDENTITY em uma tabela. Essas funções de identidade estão listadas abaixo:
- Função @@IDENTIDADE
- Função SCOPE_IDENTITY()
- Função IDENT_CURRENT
- Função IDENTIDADE
Vamos dar uma olhada nas funções IDENTITY com alguns exemplos.
Função @@IDENTIDADE
O @@IDENTITY é uma função definida pelo sistema que exibe o último valor de identidade (valor máximo de identidade utilizado) criado em uma tabela para a coluna IDENTITY na mesma sessão. Esta coluna de função retorna o valor de identidade gerado pela instrução após inserir uma nova entrada em uma tabela. Ele retorna um NULO valor quando executamos uma consulta que não cria valores IDENTITY. Sempre funciona no escopo da sessão atual. Não pode ser usado remotamente.
Exemplo
Suponha que o valor máximo de identidade atual na tabela de pessoas seja 13. Agora adicionaremos um registro na mesma sessão que aumenta o valor de identidade em um. Em seguida, usaremos a função @@IDENTITY para obter o último valor de identidade criado na mesma sessão.
Aqui está o script de código completo:
SELECT MAX(PersonID) AS maxidentity FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Brian Lara', 'Cricket', 'Male'); SELECT @@IDENTITY;
A execução do script retornará a seguinte saída, onde podemos ver que o valor máximo de identidade usado é 14.

Função SCOPE_IDENTITY()
O SCOPE_IDENTITY() é uma função definida pelo sistema para exibir o valor de identidade mais recente em uma tabela no escopo atual. Este escopo pode ser um módulo, gatilho, função ou procedimento armazenado. É semelhante à função @@IDENTITY(), exceto que esta função tem apenas um escopo limitado. A função SCOPE_IDENTITY retorna NULL se a executarmos antes da operação de inserção que gera um valor no mesmo escopo.
Exemplo
O código abaixo usa as funções @@IDENTITY e SCOPE_IDENTITY() na mesma sessão. Este exemplo exibirá primeiro o último valor de identidade e, em seguida, inserirá uma linha na tabela. Em seguida, ele executa ambas as funções de identidade.
SELECT MAX(PersonID) AS maxid FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Jennifer Winset', 'Actoress', 'Female'); SELECT SCOPE_IDENTITY(); SELECT @@IDENTITY;
A execução do código exibirá o mesmo valor na sessão atual e um escopo semelhante. Veja a imagem de saída abaixo:

Agora veremos como ambas as funções são diferentes com um exemplo. Primeiro, criaremos duas tabelas chamadas dados_dofuncionário e departamento usando a declaração abaixo:
CREATE TABLE employee_data ( emp_id INT IDENTITY(1, 1) PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL ) GO CREATE TABLE department ( department_id INT IDENTITY(100, 5) PRIMARY KEY, department_name VARCHAR(20) NULL );
A seguir, criamos um gatilho INSERT na tabela Employee_data. Este gatilho é invocado para inserir uma linha na tabela de departamento sempre que inserimos uma linha na tabela Employee_data.
A consulta abaixo cria um gatilho para inserir um valor padrão 'ISTO' na tabela de departamento em cada consulta de inserção na tabela Employee_Data:
10 ml é quanto
CREATE TRIGGER Insert_Department ON employee_data FOR INSERT AS BEGIN INSERT INTO department VALUES ('IT') END;
Depois de criar um gatilho, inseriremos um registro na tabela Employee_Data e veremos a saída das funções @@IDENTITY e SCOPE_IDENTITY().
INSERT INTO employee_data VALUES ('John Mathew');
A execução da consulta adicionará uma linha à tabela Employee_Data e gerará um valor de identidade na mesma sessão. Depois que a consulta de inserção é executada na tabela Employee_Data, ela chama automaticamente um gatilho para adicionar uma linha na tabela Department. O valor inicial da identidade é 1 para Employee_Data e 100 para a tabela Department.
Por fim, executamos as instruções abaixo que exibem a saída 100 para a função SELECT @@IDENTITY e 1 para a função SCOPE_IDENTITY porque retornam o valor de identidade apenas no mesmo escopo.
SELECT MAX(emp_id) FROM employee_data SELECT MAX(department_id) FROM department SELECT @@IDENTITY SELECT SCOPE_IDENTITY()
Aqui está o resultado:

Função IDENT_CURRENT()
O IDENT_CURRENT é uma função definida pelo sistema para exibir o valor IDENTITY mais recente gerado para uma determinada tabela em qualquer conexão. Esta função não considera o escopo da consulta SQL que cria o valor da identidade. Esta função requer o nome da tabela para a qual queremos obter o valor de identidade.
Exemplo
Podemos entender isso abrindo primeiro as duas janelas de conexão. Iremos inserir um registro na primeira janela que gera o valor de identidade 15 na tabela pessoa. A seguir, podemos verificar esse valor de identidade em outra janela de conexão onde podemos ver a mesma saída. Aqui está o código completo:
1st Connection Window INSERT INTO person(Fullname, Occupation, Gender) VALUES('John Doe', 'Engineer', 'Male'); GO SELECT MAX(PersonID) AS maxid FROM person; 2nd Connection Window SELECT MAX(PersonID) AS maxid FROM person; GO SELECT IDENT_CURRENT('person') AS identity_value;
A execução dos códigos acima em duas janelas diferentes exibirá o mesmo valor de identidade.

Função IDENTIDADE()
A função IDENTITY() é uma função definida pelo sistema usado para inserir uma coluna de identidade em uma nova tabela . Esta função é diferente da propriedade IDENTITY que usamos com as instruções CREATE TABLE e ALTER TABLE. Podemos usar esta função apenas em uma instrução SELECT INTO, que é usada durante a transferência de dados de uma tabela para outra.
A sintaxe a seguir ilustra o uso desta função no SQL Server:
IDENTITY (data_type , seed , increment) AS column_name
Se uma tabela de origem tiver uma coluna IDENTITY, a tabela formada com um comando SELECT INTO a herdará por padrão. Por exemplo , criamos anteriormente uma tabela person com uma coluna de identidade. Suponha que criamos uma nova tabela que herda a tabela person usando as instruções SELECT INTO com a função IDENTITY(). Nesse caso, obteremos um erro porque a tabela de origem já possui uma coluna de identidade. Veja a consulta abaixo:
SELECT IDENTITY(INT, 100, 2) AS NEW_ID, PersonID, Fullname, Occupation, Gender INTO person_info FROM person;
A execução da instrução acima retornará a seguinte mensagem de erro:

Vamos criar uma nova tabela sem propriedade de identidade usando a instrução abaixo:
CREATE TABLE student_data ( roll_no INT PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL )
Em seguida, copie esta tabela usando a instrução SELECT INTO incluindo a função IDENTITY da seguinte forma:
SELECT IDENTITY(INT, 100, 1) AS student_id, roll_no, fullname INTO temp_data FROM student_data;
Depois que a instrução for executada, podemos verificá-la usando o sp_help comando que exibe propriedades da tabela.

Você pode ver a coluna IDENTIDADE no TENTÁVEL propriedades de acordo com as condições especificadas.
Se usarmos esta função com a instrução SELECT, o SQL Server apresentará a seguinte mensagem de erro:
Msg 177, Nível 15, Estado 1, Linha 2 A função IDENTITY só pode ser usada quando a instrução SELECT possui uma cláusula INTO.
Reutilizando valores IDENTITY
Não podemos reutilizar os valores de identidade na tabela do SQL Server. Quando excluímos qualquer linha da tabela da coluna de identidade, uma lacuna será criada na coluna de identidade. Além disso, o SQL Server criará uma lacuna quando inserirmos uma nova linha na coluna de identidade e a instrução falhar ou for revertida. A lacuna indica que os valores de identidade foram perdidos e não podem ser gerados novamente na coluna IDENTITY.
Considere o exemplo abaixo para entendê-lo na prática. Já temos uma tabela person contendo os seguintes dados:

A seguir, criaremos mais duas tabelas chamadas 'posição' , e ' posição_pessoa 'usando a seguinte instrução:
CREATE TABLE POSITION ( PositionID INT IDENTITY (1, 1) PRIMARY KEY, Position_name VARCHAR (255) NOT NULL ); CREATE TABLE person_position ( PersonID INT, PositionID INT, PRIMARY KEY (PersonID, PositionID), FOREIGN KEY (PersonID) REFERENCES person (PersonID), FOREIGN KEY (PositionID) REFERENCES POSITION (PositionID) );
A seguir, tentamos inserir um novo registro na tabela person e atribuir-lhe uma posição adicionando uma nova linha na tabela person_position. Faremos isso usando o extrato de transação conforme abaixo:
BEGIN TRANSACTION BEGIN TRY -- insert a new row into the person table INSERT INTO person (Fullname, Occupation, Gender) VALUES('Joan Smith', 'Manager', 'Male'); -- assign a position to a new person INSERT INTO person_position (PersonID, PositionID) VALUES(@@IDENTITY, 10); END TRY BEGIN CATCH IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION; END CATCH IF @@TRANCOUNT > 0 COMMIT TRANSACTION;
O script do código de transação acima executa a primeira instrução de inserção com sucesso. Mas a segunda instrução falhou porque não havia posição com id dez na tabela de posições. Conseqüentemente, toda a transação foi revertida.
Como o valor máximo de identidade na coluna PersonID é 16, a primeira instrução de inserção consumiu o valor de identidade 17 e, em seguida, a transação foi revertida. Portanto, se inserirmos a próxima linha na tabela Person, o próximo valor de identidade será 18. Execute a instrução abaixo:
INSERT INTO person(Fullname, Occupation, Gender) VALUES('Peter Drucker',' Writer', 'Female');
Depois de verificar a tabela person novamente, vemos que o registro recém-adicionado contém o valor de identidade 18.

Duas colunas IDENTITY em uma única tabela
Tecnicamente, não é possível criar duas colunas de identidade numa única tabela. Se fizermos isso, o SQL Server gerará um erro. Veja a seguinte consulta:
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, ID2 INT IDENTITY (100, 1) NOT NULL )
Ao executarmos este código, veremos o seguinte erro:

No entanto, podemos criar duas colunas de identidade em uma única tabela usando a coluna computada. A consulta a seguir cria uma tabela com uma coluna computada que usa a coluna de identidade original e a diminui em 1.
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, SecondID AS 10000-ID1, Descriptions VARCHAR(60) )
A seguir, adicionaremos alguns dados a esta tabela usando o comando abaixo:
INSERT INTO TwoIdentityTable (Descriptions) VALUES ('Javatpoint provides best educational tutorials'), ('www.javatpoint.com')
Finalmente, verificamos os dados da tabela usando a instrução SELECT. Ele retorna a seguinte saída:

Podemos ver na imagem como a coluna SecondID atua como uma segunda coluna de identidade, diminuindo em dez a partir do valor inicial de 9990.
Equívocos da coluna IDENTITY do SQL Server
O usuário DBA tem muitos conceitos errados em relação às colunas de identidade do SQL Server. A seguir está a lista dos equívocos mais comuns em relação às colunas de identidade que seriam vistas:
A coluna IDENTITY é UNIQUE: De acordo com a documentação oficial do SQL Server, a propriedade de identidade não pode garantir que o valor da coluna seja exclusivo. Devemos usar uma PRIMARY KEY, uma restrição UNIQUE ou um índice UNIQUE para impor a exclusividade da coluna.
A coluna IDENTITY gera números consecutivos: A documentação oficial afirma claramente que os valores atribuídos na coluna de identidade podem ser perdidos em caso de falha do banco de dados ou reinicialização do servidor. Isso pode causar lacunas no valor da identidade durante a inserção. A lacuna também pode ser criada quando excluímos o valor da tabela ou a instrução insert é revertida. Os valores que geram lacunas não podem ser utilizados posteriormente.
A coluna IDENTITY não pode gerar automaticamente valores existentes: Não é possível que a coluna de identidade gere automaticamente valores existentes até que a propriedade de identidade seja propagada novamente usando o comando DBCC CHECKIDENT. Isso nos permite ajustar o valor inicial (valor inicial da linha) da propriedade de identidade. Após executar este comando, o SQL Server não irá verificar os valores recém-criados já presentes na tabela ou não.
A coluna IDENTITY como PRIMARY KEY é suficiente para identificar a linha: Se uma chave primária contiver a coluna de identidade na tabela sem quaisquer outras restrições exclusivas, a coluna poderá armazenar valores duplicados e evitar a exclusividade da coluna. Como sabemos, a chave primária não pode armazenar valores duplicados, mas a coluna de identidade pode armazenar valores duplicados; é recomendado não usar a chave primária e a propriedade de identidade na mesma coluna.
Usando a ferramenta errada para recuperar os valores de identidade após uma inserção: Também é um equívoco comum sobre o desconhecimento das diferenças entre as funções @@IDENTITY, SCOPE_IDENTITY(), IDENT_CURRENT e IDENTITY() para obter o valor de identidade inserido diretamente na instrução que acabamos de executar.
Diferença entre SEQUÊNCIA e IDENTIDADE
Usamos SEQUENCE e IDENTITY para gerar números automáticos. No entanto, tem algumas diferenças, e a principal diferença é que a identidade depende da tabela, enquanto a sequência não. Vamos resumir suas diferenças na forma tabular:
| IDENTIDADE | SEQÜÊNCIA |
|---|---|
| A propriedade de identidade é usada para uma tabela específica e não pode ser compartilhada com outras tabelas. | Um DBA define o objeto de sequência que pode ser compartilhado entre várias tabelas porque é independente de uma tabela. |
| Esta propriedade gera valores automaticamente cada vez que a instrução insert é executada na tabela. | Ele usa a cláusula NEXT VALUE FOR para gerar o próximo valor para um objeto de sequência. |
| O SQL Server não redefine o valor da coluna da propriedade de identidade para seu valor inicial. | O SQL Server pode redefinir o valor do objeto de sequência. |
| Não podemos definir o valor máximo para a propriedade de identidade. | Podemos definir o valor máximo para o objeto de sequência. |
| Ele é introduzido no SQL Server 2000. | Ele é introduzido no SQL Server 2012. |
| Esta propriedade não pode gerar valor de identidade em ordem decrescente. | Pode gerar valores em ordem decrescente. |
Conclusão
Este artigo fornecerá uma visão geral completa da propriedade IDENTITY no SQL Server. Aqui aprendemos como e quando a propriedade de identidade é usada, suas diferentes funções, equívocos e como ela difere da sequência.