A pesquisa desinformada é uma classe de algoritmos de pesquisa de uso geral que opera por força bruta. Algoritmos de busca desinformados não possuem informações adicionais sobre o estado ou espaço de busca além de como percorrer a árvore, por isso também são chamados de busca cega.
A seguir estão os vários tipos de algoritmos de pesquisa desinformados:
1. Pesquisa ampla:
- A pesquisa em largura é a estratégia de pesquisa mais comum para percorrer uma árvore ou gráfico. Este algoritmo pesquisa em largura em uma árvore ou gráfico, por isso é chamado de pesquisa em largura.
- O algoritmo BFS inicia a pesquisa a partir do nó raiz da árvore e expande todos os nós sucessores no nível atual antes de passar para os nós do próximo nível.
- O algoritmo de pesquisa em largura é um exemplo de algoritmo de pesquisa em gráfico geral.
- Pesquisa ampla implementada usando estrutura de dados de fila FIFO.
Vantagens:
- O BFS fornecerá uma solução se existir alguma solução.
- Se houver mais de uma solução para um determinado problema, o BFS fornecerá a solução mínima que requer o menor número de etapas.
Desvantagens:
- Requer muita memória, pois cada nível da árvore deve ser salvo na memória para expandir o próximo nível.
- O BFS precisa de muito tempo se a solução estiver longe do nó raiz.
Exemplo:
Na estrutura de árvore abaixo, mostramos a travessia da árvore usando o algoritmo BFS do nó raiz S até o nó objetivo K. O algoritmo de pesquisa BFS percorre em camadas, portanto seguirá o caminho mostrado pela seta pontilhada, e o caminho percorrido será:
S---> A--->B---->C--->D---->G--->H--->E---->F---->I---->K
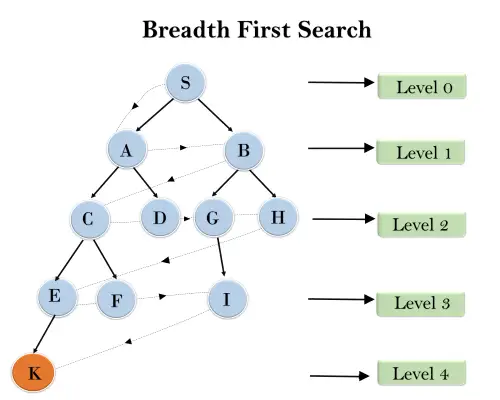
Complexidade de tempo: A complexidade temporal do algoritmo BFS pode ser obtida pelo número de nós percorridos no BFS até o nó mais raso. Onde d = profundidade da solução mais rasa e b é um nó em cada estado.
T(b) = 1+b2+b3+.......+bd=O(bd)
Complexidade Espacial: A complexidade espacial do algoritmo BFS é dada pelo tamanho da memória da fronteira que é O(bd).
Completude: O BFS está completo, o que significa que se o nó objetivo mais raso estiver em alguma profundidade finita, então o BFS encontrará uma solução.
Otimização: O BFS é ideal se o custo do caminho for uma função não decrescente da profundidade do nó.
2. Pesquisa em profundidade
- A pesquisa em profundidade é um algoritmo recursivo para percorrer uma estrutura de dados em árvore ou gráfico.
- É chamada de busca em profundidade porque começa no nó raiz e segue cada caminho até seu nó de maior profundidade antes de passar para o próximo caminho.
- O DFS usa uma estrutura de dados de pilha para sua implementação.
- O processo do algoritmo DFS é semelhante ao algoritmo BFS.
Nota: Backtracking é uma técnica de algoritmo para encontrar todas as soluções possíveis usando recursão.
Vantagem:
- O DFS requer muito menos memória, pois só precisa armazenar uma pilha de nós no caminho do nó raiz até o nó atual.
- Leva menos tempo para chegar ao nó de destino do que o algoritmo BFS (se ele percorrer o caminho certo).
Desvantagem:
- Existe a possibilidade de que muitos estados continuem a ocorrer e não há garantia de encontrar a solução.
- O algoritmo DFS faz pesquisas profundas e às vezes pode ir para o loop infinito.
Exemplo:
Na árvore de pesquisa abaixo, mostramos o fluxo da pesquisa em profundidade e seguirá a ordem:
Nó raiz ---> Nó esquerdo ----> Nó direito.
Ele começará a pesquisar a partir do nó raiz S e percorrerá A, depois B, depois D e E, após percorrer E, ele retrocederá na árvore, pois E não tem outro sucessor e ainda assim o nó objetivo não foi encontrado. Após retroceder, ele percorrerá o nó C e depois G, e aqui terminará quando encontrou o nó objetivo.

Completude: O algoritmo de pesquisa DFS é completo em um espaço de estado finito, pois expandirá cada nó dentro de uma árvore de pesquisa limitada.
Complexidade de tempo: A complexidade de tempo do DFS será equivalente ao nó percorrido pelo algoritmo. É dado por:
T(n)= 1+ n2+n3+.........+neu=O(neu)
Onde, m = profundidade máxima de qualquer nó e pode ser muito maior que d (profundidade de solução mais rasa)
Complexidade Espacial: O algoritmo DFS precisa armazenar apenas um único caminho do nó raiz, portanto, a complexidade de espaço do DFS é equivalente ao tamanho do conjunto marginal, que é Sobre .
Ótimo: O algoritmo de busca DFS não é ideal, pois pode gerar um grande número de etapas ou alto custo para chegar ao nó objetivo.
3. Algoritmo de pesquisa com profundidade limitada:
Um algoritmo de pesquisa com profundidade limitada é semelhante à pesquisa em profundidade com um limite predeterminado. A pesquisa em profundidade limitada pode resolver a desvantagem do caminho infinito na pesquisa em profundidade. Neste algoritmo, o nó no limite de profundidade será tratado como se não tivesse mais nós sucessores.
string de concatenação em java
A pesquisa com profundidade limitada pode ser encerrada com duas condições de falha:
- Valor de falha padrão: Indica que o problema não tem solução.
- Valor de falha de corte: Não define solução para o problema dentro de um determinado limite de profundidade.
Vantagens:
A pesquisa com profundidade limitada é eficiente em termos de memória.
Desvantagens:
- A pesquisa com profundidade limitada também tem a desvantagem de ser incompleta.
- Pode não ser ideal se o problema tiver mais de uma solução.
Exemplo:

Completude: O algoritmo de busca DLS está completo se a solução estiver acima do limite de profundidade.
Complexidade de tempo: A complexidade de tempo do algoritmo DLS é O(bℓ) .
Complexidade Espacial: A complexidade espacial do algoritmo DLS é O (b�ℓ) .
Ótimo: A pesquisa com profundidade limitada pode ser vista como um caso especial de DFS e também não é ideal, mesmo se ℓ>d.
4. Algoritmo de pesquisa de custo uniforme:
A pesquisa de custo uniforme é um algoritmo de pesquisa usado para percorrer uma árvore ou gráfico ponderado. Este algoritmo entra em ação quando um custo diferente está disponível para cada aresta. O objetivo principal da busca de custo uniforme é encontrar um caminho para o nó objetivo que tenha o menor custo cumulativo. A pesquisa de custo uniforme expande os nós de acordo com os custos do caminho do nó raiz. Ele pode ser usado para resolver qualquer gráfico/árvore onde o custo ideal seja exigido. Um algoritmo de busca de custo uniforme é implementado pela fila de prioridade. Dá prioridade máxima ao menor custo cumulativo. A pesquisa de custo uniforme é equivalente ao algoritmo BFS se o custo do caminho de todas as arestas for o mesmo.
Vantagens:
- A busca de custo uniforme é ótima porque em cada estado é escolhido o caminho com o menor custo.
Desvantagens:
- Ele não se preocupa com o número de etapas envolvidas na pesquisa e apenas se preocupa com o custo do caminho. Devido a isso, este algoritmo pode ficar preso em um loop infinito.
Exemplo:

Completude:
A pesquisa de custo uniforme está completa, por exemplo, se houver uma solução, o UCS a encontrará.
Complexidade de tempo:
Deixe C* é o custo da solução ótima , e e é cada passo para se aproximar do nó de meta. Então o número de etapas é = C*/ε+1. Aqui tomamos +1, pois começamos do estado 0 e terminamos em C*/ε.
Conseqüentemente, a complexidade de tempo do pior caso da pesquisa de custo uniforme é O(b1 + [C*/e])/ .
Complexidade Espacial:
A mesma lógica se aplica à complexidade espacial, portanto, a complexidade espacial de pior caso da pesquisa de custo uniforme é O(b1 + [C*/e]) .
Ótimo:
A pesquisa de custo uniforme é sempre ótima, pois seleciona apenas um caminho com o menor custo.
5. Aprofundamento iterativo Pesquisa em profundidade:
O algoritmo de aprofundamento iterativo é uma combinação dos algoritmos DFS e BFS. Este algoritmo de busca descobre o melhor limite de profundidade e faz isso aumentando gradativamente o limite até que um objetivo seja encontrado.
Este algoritmo realiza uma pesquisa em profundidade até um certo 'limite de profundidade' e continua aumentando o limite de profundidade após cada iteração até que o nó objetivo seja encontrado.
Este algoritmo de pesquisa combina os benefícios da pesquisa rápida da pesquisa em largura e da eficiência de memória da pesquisa em profundidade.
O algoritmo de busca iterativo é útil na busca não informada quando o espaço de busca é grande e a profundidade do nó objetivo é desconhecida.
Vantagens:
- Ele combina os benefícios do algoritmo de pesquisa BFS e DFS em termos de pesquisa rápida e eficiência de memória.
Desvantagens:
- A principal desvantagem do IDDFS é que ele repete todo o trabalho da fase anterior.
Exemplo:
A estrutura em árvore a seguir mostra a pesquisa em profundidade de aprofundamento iterativo. O algoritmo IDDFS realiza várias iterações até encontrar o nó objetivo. A iteração realizada pelo algoritmo é dada como:

1ª Iteração-----> A
2ª Iteração ----> A, B, C
3ª Iteração ------> A, B, D, E, C, F, G
4ª Iteração ------> A, B, D, H, I, E, C, F, K, G
Na quarta iteração, o algoritmo encontrará o nó objetivo.
Completude:
Este algoritmo está completo se o fator de ramificação for finito.
Complexidade de tempo:
Suponhamos que b seja o fator de ramificação e a profundidade seja d, então a complexidade de tempo do pior caso é O(bd) .
Complexidade Espacial:
A complexidade espacial do IDDFS será O(bd) .
Ótimo:
O algoritmo IDDFS é ideal se o custo do caminho for uma função não decrescente da profundidade do nó.
6. Algoritmo de pesquisa bidirecional:
O algoritmo de pesquisa bidirecional executa duas pesquisas simultâneas, uma do estado inicial chamada de pesquisa direta e outra do nó objetivo chamada de pesquisa regressiva, para encontrar o nó objetivo. A pesquisa bidirecional substitui um único gráfico de pesquisa por dois pequenos subgrafos em que um inicia a pesquisa a partir de um vértice inicial e outro inicia a partir do vértice objetivo. A pesquisa termina quando esses dois gráficos se cruzam.
A pesquisa bidirecional pode usar técnicas de pesquisa como BFS, DFS, DLS, etc.
sabe
Vantagens:
- A pesquisa bidirecional é rápida.
- A pesquisa bidirecional requer menos memória
Desvantagens:
- A implementação da árvore de busca bidirecional é difícil.
Exemplo:
Na árvore de pesquisa abaixo, o algoritmo de pesquisa bidirecional é aplicado. Este algoritmo divide um gráfico/árvore em dois subgráficos. Ele começa a percorrer o nó 1 na direção para frente e começa no nó objetivo 16 na direção para trás.
O algoritmo termina no nó 9, onde duas buscas se encontram.

Completude: A pesquisa bidirecional estará completa se usarmos BFS em ambas as pesquisas.
Complexidade de tempo: A complexidade de tempo da pesquisa bidirecional usando BFS é O(bd) .
Complexidade Espacial: A complexidade espacial da pesquisa bidirecional é O(bd) .
Ótimo: A pesquisa bidirecional é ideal.