Clustering ou análise de cluster é uma técnica de aprendizado de máquina que agrupa o conjunto de dados não rotulado. Pode ser definido como 'Uma forma de agrupar os pontos de dados em diferentes clusters, consistindo em pontos de dados semelhantes. Os objetos com possíveis semelhanças permanecem em um grupo que tem menos ou nenhuma semelhança com outro grupo.'
Ele faz isso encontrando alguns padrões semelhantes no conjunto de dados não rotulado, como forma, tamanho, cor, comportamento, etc., e os divide de acordo com a presença e ausência desses padrões semelhantes.
É um aprendizagem não supervisionada método, portanto, nenhuma supervisão é fornecida ao algoritmo e ele lida com o conjunto de dados não rotulado.
Depois de aplicar esta técnica de clustering, cada cluster ou grupo recebe um ID de cluster. O sistema de ML pode usar esse ID para simplificar o processamento de conjuntos de dados grandes e complexos.
gimp excluindo plano de fundo
A técnica de agrupamento é comumente usada para análise estatística de dados.
Nota: O clustering está em algum lugar semelhante ao algoritmo de classificação , mas a diferença é o tipo de conjunto de dados que estamos usando. Na classificação, trabalhamos com o conjunto de dados rotulado, enquanto no clustering trabalhamos com o conjunto de dados não rotulado.
Exemplo : Vamos entender a técnica de agrupamento com o exemplo do mundo real de Mall: Quando visitamos qualquer shopping center, podemos observar que as coisas com uso semelhante são agrupadas. Assim como as camisetas são agrupadas em uma seção e as calças em outras seções, da mesma forma, nas seções de vegetais, maçãs, bananas, mangas, etc., são agrupadas em seções separadas, para que possamos descobrir facilmente as coisas. A técnica de agrupamento também funciona da mesma maneira. Outros exemplos de agrupamento são agrupar documentos de acordo com o tópico.
A técnica de clustering pode ser amplamente utilizada em diversas tarefas. Alguns usos mais comuns desta técnica são:
- Segmentação de mercado
- Análise de dados estatísticos
- Análise de redes sociais
- Segmentação de imagens
- Detecção de anomalias, etc.
Além desses usos gerais, é usado pelo Amazonas em seu sistema de recomendação para fornecer recomendações de acordo com pesquisas anteriores de produtos. Netflix também usa essa técnica para recomendar filmes e séries da web aos seus usuários de acordo com o histórico de exibição.
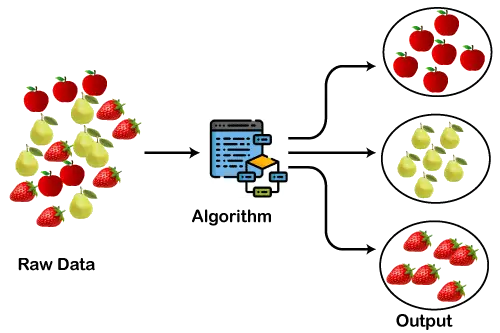
O diagrama abaixo explica o funcionamento do algoritmo de cluster. Podemos ver que as diferentes frutas estão divididas em vários grupos com propriedades semelhantes.
Tipos de métodos de cluster
Os métodos de agrupamento são amplamente divididos em Clustering difícil (o ponto de dados pertence a apenas um grupo) e Clustering suave (os pontos de dados também podem pertencer a outro grupo). Mas também existem outras abordagens de Clustering. Abaixo estão os principais métodos de cluster usados em aprendizado de máquina:
senão java
Clustering de particionamento
É um tipo de clustering que divide os dados em grupos não hierárquicos. Também é conhecido como método baseado em centróide . O exemplo mais comum de clustering de particionamento é o Algoritmo de agrupamento K-Means .
Neste tipo, o conjunto de dados é dividido em um conjunto de k grupos, onde K é utilizado para definir o número de grupos pré-definidos. O centro do cluster é criado de forma que a distância entre os pontos de dados de um cluster seja mínima em comparação com outro centróide do cluster.
linux menta canela vs companheiro

Clustering baseado em densidade
O método de agrupamento baseado em densidade conecta as áreas altamente densas em agrupamentos, e as distribuições de formato arbitrário são formadas desde que a região densa possa ser conectada. Este algoritmo faz isso identificando diferentes clusters no conjunto de dados e conecta as áreas de alta densidade em clusters. As áreas densas no espaço de dados são divididas entre si por áreas mais esparsas.
Esses algoritmos podem enfrentar dificuldade em agrupar os pontos de dados se o conjunto de dados tiver densidades variadas e dimensões altas.

Clustering baseado em modelo de distribuição
No método de agrupamento baseado em modelo de distribuição, os dados são divididos com base na probabilidade de como um conjunto de dados pertence a uma distribuição específica. O agrupamento é feito assumindo algumas distribuições comumente Distribuição gaussiana .
O exemplo desse tipo é o Algoritmo de cluster de maximização de expectativa que usa Modelos de Mistura Gaussiana (GMM).

Agrupamento hierárquico
O cluster hierárquico pode ser usado como uma alternativa ao cluster particionado, pois não há necessidade de pré-especificar o número de clusters a serem criados. Nesta técnica, o conjunto de dados é dividido em clusters para criar uma estrutura semelhante a uma árvore, também chamada de dendograma . As observações ou qualquer número de agrupamentos podem ser selecionados cortando a árvore no nível correto. O exemplo mais comum deste método é o Algoritmo hierárquico aglomerativo .

Cluster difuso
Clustering difuso é um tipo de método flexível no qual um objeto de dados pode pertencer a mais de um grupo ou cluster. Cada conjunto de dados possui um conjunto de coeficientes de pertinência, que dependem do grau de pertinência de um cluster. Algoritmo Fuzzy C-means é o exemplo deste tipo de clustering; às vezes também é conhecido como algoritmo Fuzzy k-means.
Algoritmos de agrupamento
Os algoritmos de Clustering podem ser divididos com base em seus modelos explicados acima. Existem diferentes tipos de algoritmos de clustering publicados, mas apenas alguns são comumente usados. O algoritmo de agrupamento é baseado no tipo de dados que estamos usando. Por exemplo, alguns algoritmos precisam adivinhar o número de clusters em um determinado conjunto de dados, enquanto outros são obrigados a encontrar a distância mínima entre as observações do conjunto de dados.
Aqui estamos discutindo principalmente algoritmos de clustering populares que são amplamente usados em aprendizado de máquina:
quem criou a escola
Aplicações de clustering
Abaixo estão algumas aplicações comumente conhecidas da técnica de cluster em aprendizado de máquina: