- Redshift é um serviço de data warehouse rápido e poderoso, totalmente gerenciado e em escala de petabytes na nuvem.
- Os clientes podem usar o Redshift por apenas US$ 0,25 por hora, sem compromissos ou custos iniciais, e escalar para um petabyte ou mais por US$ 1.000 por terabyte por ano.
OLAP
OLAP é um Sistema de processamento de análises on-line usado pelo Desvio para o vermelho .
Exemplo de transação OLAP:
Suponha que queiramos calcular o lucro líquido para EMEA e Pacífico para o produto de rádio digital. Isso requer extrair um grande número de registros. A seguir estão os registros necessários para calcular o lucro líquido:
- Soma dos rádios vendidos na EMEA.
- Soma dos rádios vendidos no Pacífico.
- Custo unitário do rádio em cada região.
- Preço de venda de cada rádio
- Preço de venda - custo unitário
As consultas complexas são necessárias para buscar os registros fornecidos acima. Os bancos de dados de Data Warehousing usam diferentes tipos de arquitetura, tanto do ponto de vista do banco de dados quanto da camada de infraestrutura.
Configuração do Redshift
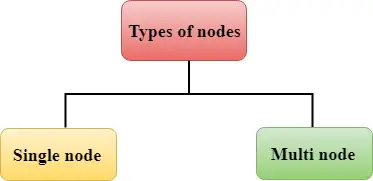
Redshift consiste em dois tipos de nós:
Nó único: Um único nó armazena até 160 GB.
Multinó: Multinó é um nó que consiste em mais de um nó. É de dois tipos:
Ele gerencia as conexões do cliente e recebe consultas. Um nó líder recebe as consultas dos aplicativos clientes, analisa as consultas e desenvolve os planos de execução. Ele coordena a execução paralela desses planos com o nó de computação e combina os resultados intermediários de todos os nós, e então retorna o resultado final para a aplicação cliente.
Um nó de computação executa os planos de execução e, em seguida, os resultados intermediários são enviados ao nó líder para agregação antes de serem enviados de volta ao aplicativo cliente. Pode ter até 128 nós de computação.
Vamos entender o conceito de nó líder e nós de computação por meio de um exemplo.
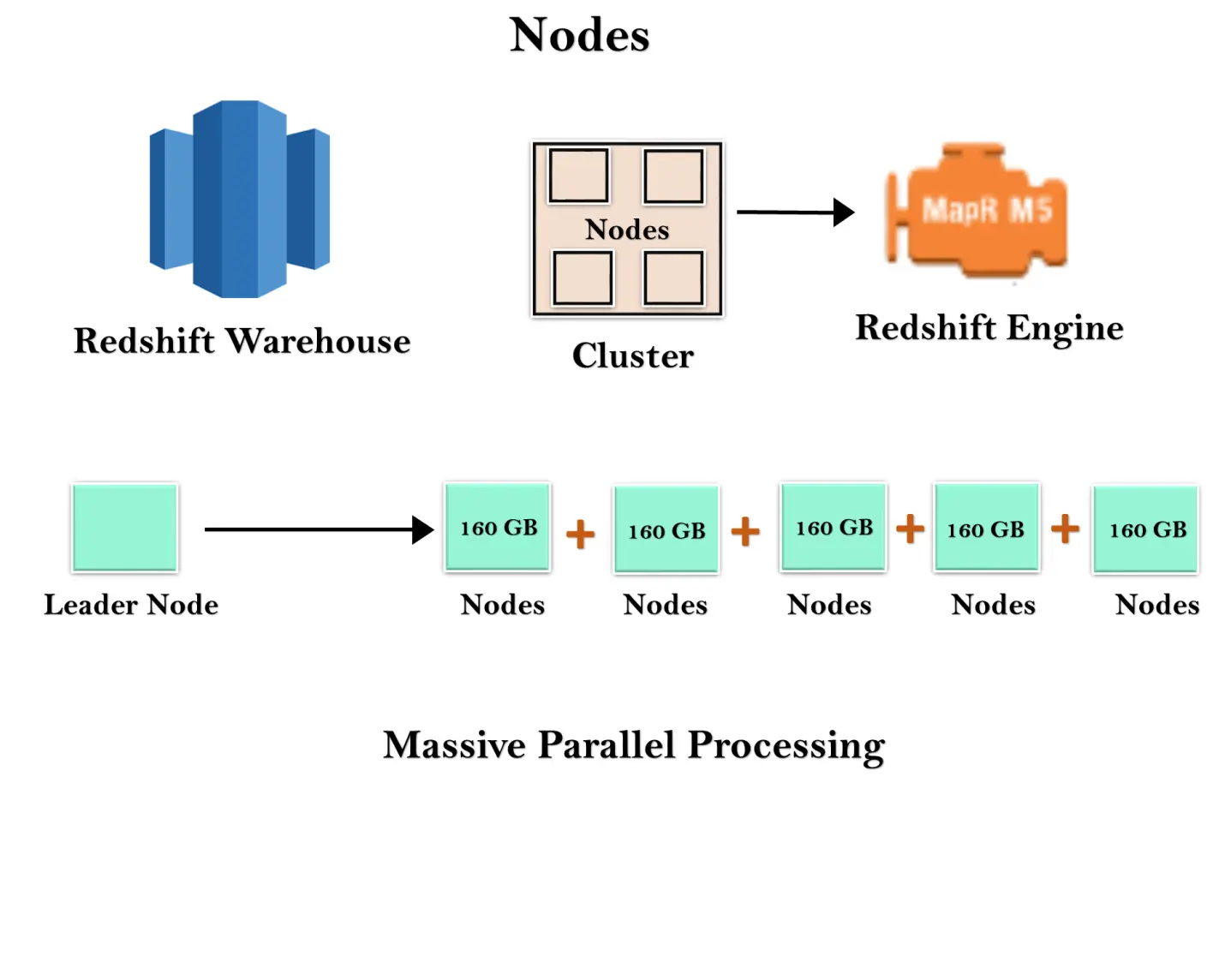
O armazém Redshift é uma coleção de recursos de computação conhecidos como nós, e esses nós são organizados em um grupo conhecido como cluster. Cada cluster é executado em um Redshift Engine que contém um ou mais bancos de dados.
Quando você inicia uma instância do Redshift, ela começa com um único nó de 160 GB. Quando quiser crescer, você pode adicionar nós adicionais para aproveitar as vantagens do processamento paralelo. Você tem um nó líder que gerencia vários nós. O nó líder lida com a conexão do cliente, bem como com os nós de computação. Ele armazena os dados em nós de computação e executa a consulta.
Por que o Redshift é 10 vezes mais rápido
O Redshift é 10 vezes mais rápido pelos seguintes motivos:
Em vez de armazenar dados como uma série de linhas, o Amazon Redshift organiza os dados por coluna. Os sistemas baseados em linhas são ideais para processamento de transações, enquanto os sistemas baseados em colunas são ideais para armazenamento e análise de dados, onde as consultas geralmente envolvem agregações realizadas em grandes conjuntos de dados. Como apenas as colunas envolvidas nas consultas são processadas e os dados colunares são armazenados sequencialmente em uma mídia de armazenamento, os sistemas baseados em colunas requerem menos E/S, melhorando assim o desempenho da consulta.
Os armazenamentos de dados colunares podem ser compactados muito mais do que os armazenamentos de dados baseados em linhas porque dados semelhantes são armazenados sequencialmente no disco. O Amazon Redshift emprega diversas técnicas de compactação e muitas vezes pode obter compactação significativa em relação aos armazenamentos de dados relacionais tradicionais.
O Amazon Redshift não requer índices ou visualizações materializadas, portanto, requer menos espaço do que os sistemas de banco de dados relacionais tradicionais. Ao carregar dados em uma tabela vazia, o Amazon Redshift faz amostras dos dados automaticamente e seleciona a técnica de compactação mais apropriada.
O Amazon Redshift distribui automaticamente os dados e carrega a consulta em vários nós. Um Amazon Redshift facilita a adição de novos nós ao seu data warehouse, o que nos permite obter um desempenho de consulta mais rápido à medida que seu data warehouse cresce.
Recursos do Redshift
Os recursos do Redshift são fornecidos abaixo:
referenciar tipos de dados em java
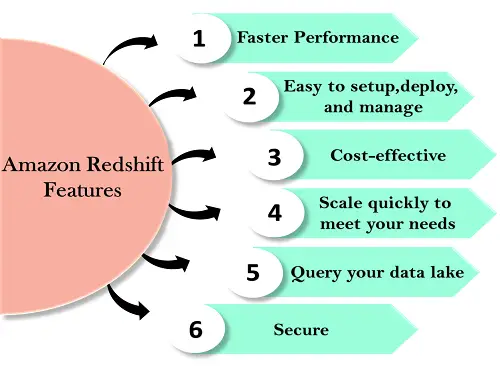
O Redshift é simples de configurar e operar. Você pode implantar um novo data warehouse com apenas alguns cliques no Console AWS, e o Redshift provisiona automaticamente a infraestrutura para você. Na AWS, todas as tarefas administrativas são automatizadas, como backups e replicação, você precisa focar nos seus dados, não na administração.
O Redshift faz backup automaticamente de seus dados para o S3. Você também pode replicar os snapshots no S3 em outra região para qualquer recuperação de desastres.
O Amazon Redshift é o serviço de data warehouse com melhor custo-benefício, pois você precisa pagar apenas pelo que usar.
Seus custos começam em US$ 0,25 por hora, sem compromisso e sem custos iniciais, e podem chegar a US$ 250 por terabyte por ano.
O Amazon Redshift é o único serviço de data warehouse que oferece preços sob demanda sem custos iniciais e também oferece preços de instâncias reservadas que economizam até 75% com prazo de 1 a 3 anos.
Você pode escolher qualquer um dos dois nós para otimizar o Redshift.
O nó de computação denso pode criar data warehouses de alto desempenho usando CPUs rápidas, uma grande quantidade de RAM e discos de estado sólido.
Se quiser reduzir o custo, você pode usar o nó de armazenamento denso. Ele cria um data warehouse econômico usando uma unidade de disco rígido maior.
O Amazon Redshift aumenta ou diminui automaticamente os nós de acordo com as mudanças necessárias. Com apenas alguns cliques no Console AWS ou uma única chamada de API, você pode alterar facilmente o número de nós em um data warehouse.
É um recurso do Redshift que permite executar consultas em exabytes de dados no Amazon S3. Amazon S3 é um sistema de dados seguro e econômico para armazenar dados ilimitados em um formato aberto.
É um recurso do Redshift que significa que múltiplas consultas podem acessar os mesmos dados no Amazon S3. Ele permite que você execute consultas em vários nós, independentemente da complexidade de uma consulta ou da quantidade de dados.
O Amazon Redshift é o único data warehouse usado para consultar o data lake do Amazon S3 sem carregar dados. Isso proporciona flexibilidade ao armazenar os dados acessados com frequência no Redshift e dados não estruturados ou acessados com pouca frequência no Amazon S3.
Com algumas configurações de parâmetros, você pode configurar o Redshift para usar SSL para proteger seus dados. Você também pode ativar a criptografia, todos os dados gravados no disco serão criptografados.
O Amazon Redshift fornece armazenamento de dados em colunas, compactação e processamento paralelo para reduzir a quantidade de E/S necessária para realizar consultas. Isso melhora o desempenho da consulta.