Desde a invenção dos computadores, as pessoas têm usado o termo ' Dados 'para se referir a informações do computador, transmitidas ou armazenadas. No entanto, também existem dados em tipos de pedidos. Os dados podem ser números ou textos escritos em um pedaço de papel, na forma de bits e bytes armazenados na memória de dispositivos eletrônicos, ou fatos armazenados na mente de uma pessoa. À medida que o mundo começou a modernizar-se, estes dados tornaram-se um aspecto significativo da vida quotidiana de todos, e várias implementações permitiram armazená-los de forma diferente.
Dados é uma coleção de fatos e números ou um conjunto de valores ou valores de um formato específico que se refere a um único conjunto de valores de item. Os itens de dados são então classificados em subitens, que é o grupo de itens que não são conhecidos como a forma primária simples do item.
Vamos considerar um exemplo em que o nome de um funcionário pode ser dividido em três subitens: Primeiro, Meio e Último. No entanto, um ID atribuído a um funcionário geralmente será considerado um único item.
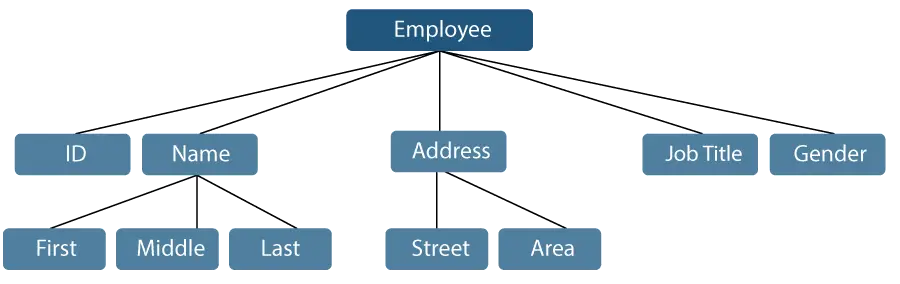
Figura 1: Representação de itens de dados
No exemplo mencionado acima, itens como ID, Idade, Gênero, Primeiro, Meio, Último, Rua, Localidade, etc., são itens de dados elementares. Por outro lado, o Nome e o Endereço são itens de dados de grupo.
O que é estrutura de dados?
Estrutura de dados é um ramo da Ciência da Computação. O estudo da estrutura de dados permite-nos compreender a organização dos dados e a gestão do fluxo de dados de forma a aumentar a eficiência de qualquer processo ou programa. Estrutura de dados é uma forma particular de armazenar e organizar dados na memória do computador para que esses dados possam ser facilmente recuperados e utilizados com eficiência no futuro, quando necessário. Os dados podem ser gerenciados de várias maneiras, como o modelo lógico ou matemático para uma organização específica de dados é conhecido como estrutura de dados.
O escopo de um modelo de dados específico depende de dois fatores:
- Primeiro, ele deve ser carregado o suficiente na estrutura para refletir a correlação definida dos dados com um objeto do mundo real.
- Em segundo lugar, a formação deve ser tão simples que se possa adaptar para processar os dados de forma eficiente sempre que necessário.
Alguns exemplos de estruturas de dados são matrizes, listas vinculadas, pilha, fila, árvores, etc. As estruturas de dados são amplamente utilizadas em quase todos os aspectos da ciência da computação, ou seja, design de compiladores, sistemas operacionais, gráficos, inteligência artificial e muito mais.
As estruturas de dados são a parte principal de muitos algoritmos de ciência da computação, pois permitem aos programadores gerenciar os dados de forma eficaz. Desempenha um papel crucial na melhoria do desempenho de um programa ou software, pois o objetivo principal do software é armazenar e recuperar os dados do usuário o mais rápido possível.
10 milhões
Terminologias básicas relacionadas a estruturas de dados
Estruturas de dados são os blocos de construção de qualquer software ou programa. Selecionar a estrutura de dados adequada para um programa é uma tarefa extremamente desafiadora para um programador.
A seguir estão algumas terminologias fundamentais usadas sempre que as estruturas de dados estão envolvidas:
| Atributos | EU IA | Nome | Gênero | Cargo |
|---|---|---|---|---|
| Valores | 1234 | Stacey M. Colina | Fêmea | Desenvolvedor de software |
Entidades com atributos semelhantes formam um Conjunto de entidades . Cada atributo de um conjunto de entidades possui um intervalo de valores, o conjunto de todos os valores possíveis que podem ser atribuídos ao atributo específico.
O termo 'informação' é por vezes utilizado para dados com determinados atributos de dados significativos ou processados.
Compreendendo a necessidade de estruturas de dados
À medida que os aplicativos se tornam mais complexos e a quantidade de dados aumenta a cada dia, o que pode levar a problemas com pesquisa de dados, velocidade de processamento, tratamento de múltiplas solicitações e muito mais. As estruturas de dados oferecem suporte a diferentes métodos para organizar, gerenciar e armazenar dados com eficiência. Com a ajuda de estruturas de dados, podemos percorrer facilmente os itens de dados. Estruturas de dados fornecem eficiência, reutilização e abstração.
Por que devemos aprender estruturas de dados?
- Estruturas de dados e algoritmos são dois dos aspectos-chave da Ciência da Computação.
- As estruturas de dados nos permitem organizar e armazenar dados, enquanto os algoritmos nos permitem processar esses dados de forma significativa.
- Aprender estruturas de dados e algoritmos nos ajudará a nos tornarmos melhores programadores.
- Seremos capazes de escrever códigos mais eficazes e confiáveis.
- Também seremos capazes de resolver problemas com mais rapidez e eficiência.
Compreendendo os objetivos das estruturas de dados
As Estruturas de Dados satisfazem dois objetivos complementares:
Compreendendo alguns recursos principais das estruturas de dados
Alguns dos recursos significativos das estruturas de dados são:
Classificação de Estruturas de Dados
Uma estrutura de dados fornece um conjunto estruturado de variáveis relacionadas entre si de várias maneiras. Ele forma a base de uma ferramenta de programação que representa o relacionamento entre os elementos de dados e permite que os programadores processem os dados de forma eficiente.
Podemos classificar as Estruturas de Dados em duas categorias:
- Estrutura de dados primitiva
- Estrutura de dados não primitiva
A figura a seguir mostra as diferentes classificações de estruturas de dados.

Figura 2: Classificações de estruturas de dados
classificação de lista de arrays
Estruturas de dados primitivas
- Essas estruturas de dados podem ser manipuladas ou operadas diretamente por instruções em nível de máquina.
- Tipos de dados básicos como Inteiro, flutuante, caractere , e boleano vêm sob as Estruturas de Dados Primitivas.
- Esses tipos de dados também são chamados Tipos de dados simples , pois contêm caracteres que não podem ser mais divididos
Estruturas de dados não primitivas
- Estas estruturas de dados não podem ser manipuladas ou operadas diretamente por instruções em nível de máquina.
- O foco dessas estruturas de dados está na formação de um conjunto de elementos de dados que seja homogêneo (mesmo tipo de dados) ou heterogêneo (diferentes tipos de dados).
- Com base na estrutura e organização dos dados, podemos dividir essas estruturas de dados em duas subcategorias -
- Estruturas de dados lineares
- Estruturas de dados não lineares
Estruturas de dados lineares
Uma estrutura de dados que preserva uma conexão linear entre seus elementos de dados é conhecida como Estrutura de Dados Linear. A organização dos dados é feita linearmente, onde cada elemento consiste nos sucessores e antecessores, exceto o primeiro e o último elemento de dados. Contudo, isso não é necessariamente verdade no caso da memória, pois o arranjo pode não ser sequencial.
Com base na alocação de memória, as Estruturas de Dados Lineares são ainda classificadas em dois tipos:
O Variedade é o melhor exemplo de Estrutura de Dados Estática, pois possui tamanho fixo e seus dados podem ser modificados posteriormente.
Listas vinculadas, pilhas , e Caudas são exemplos comuns de estruturas de dados dinâmicas
Tipos de estruturas de dados lineares
A seguir está a lista de estruturas de dados lineares que geralmente usamos:
1. Matrizes
Um Variedade é uma estrutura de dados usada para coletar vários elementos de dados do mesmo tipo de dados em uma variável. Em vez de armazenar vários valores dos mesmos tipos de dados em nomes de variáveis separados, poderíamos armazenar todos eles juntos em uma variável. Esta afirmação não implica que teremos que unir todos os valores do mesmo tipo de dados em qualquer programa em um array desse tipo de dados. Mas muitas vezes haverá momentos em que algumas variáveis específicas dos mesmos tipos de dados estarão todas relacionadas entre si de uma forma apropriada para um array.
Um Array é uma lista de elementos onde cada elemento ocupa um lugar único na lista. Os elementos de dados do array compartilham o mesmo nome de variável; no entanto, cada um carrega um número de índice diferente chamado subscrito. Podemos acessar qualquer elemento de dados da lista com a ajuda de sua localização na lista. Assim, a principal característica dos arrays a ser entendida é que os dados são armazenados em locais de memória contíguos, possibilitando aos usuários percorrer os elementos de dados do array usando seus respectivos índices.

Figura 3. Uma matriz
As matrizes podem ser classificadas em diferentes tipos:
Algumas aplicações de array:
- Podemos armazenar uma lista de elementos de dados pertencentes ao mesmo tipo de dados.
- Array atua como armazenamento auxiliar para outras estruturas de dados.
- A matriz também ajuda a armazenar elementos de dados de uma árvore binária de contagem fixa.
- Array também atua como um armazenamento de matrizes.
2. Listas vinculadas
A Lista vinculada é outro exemplo de estrutura de dados linear usada para armazenar dinamicamente uma coleção de elementos de dados. Os elementos de dados nesta estrutura de dados são representados pelos nós, conectados por meio de links ou ponteiros. Cada nó contém dois campos, o campo de informações consiste nos dados reais e o campo de ponteiro consiste no endereço dos nós subsequentes na lista. O ponteiro do último nó da lista vinculada consiste em um ponteiro nulo, pois aponta para nada. Ao contrário dos Arrays, o usuário pode ajustar dinamicamente o tamanho de uma Lista Vinculada de acordo com os requisitos.

Figura 4. Uma lista vinculada
As listas vinculadas podem ser classificadas em diferentes tipos:
codificação java instrução if else
Algumas aplicações de listas vinculadas:
- As Listas Vinculadas nos ajudam a implementar pilhas, filas, árvores binárias e gráficos de tamanho predefinido.
- Também podemos implementar a função do sistema operacional para gerenciamento dinâmico de memória.
- Listas vinculadas também permitem implementação polinomial para operações matemáticas.
- Podemos usar a lista vinculada circular para implementar sistemas operacionais ou funções de aplicativo que executam tarefas Round Robin.
- A lista vinculada circular também é útil em uma apresentação de slides em que o usuário precisa voltar ao primeiro slide após a apresentação do último slide.
- A Lista Duplamente Vinculada é utilizada para implementar botões de avançar e retroceder em um navegador para avançar e retroceder nas páginas abertas de um site.
3. Pilhas
A Pilha é uma estrutura de dados linear que segue o LIFO Princípio (Last In, First Out) que permite operações como inserção e exclusão de uma extremidade da pilha, ou seja, Topo. As pilhas podem ser implementadas com a ajuda de memória contígua, um Array, e memória não contígua, uma Lista Vinculada. Exemplos reais de pilhas são pilhas de livros, um baralho de cartas, pilhas de dinheiro e muito mais.

Figura 5. Um exemplo de pilha da vida real
A figura acima representa o exemplo real de uma Pilha onde as operações são realizadas apenas em uma extremidade, como a inserção e remoção de novos livros do topo da Pilha. Isso implica que a inserção e exclusão na pilha só podem ser feitas a partir do topo da pilha. Podemos acessar apenas os topos da pilha a qualquer momento.
As operações primárias na pilha são as seguintes:

Figura 6. Uma pilha
Algumas aplicações de pilhas:
- A pilha é usada como estrutura de armazenamento temporário para operações recursivas.
- Stack também é utilizado como estrutura de armazenamento auxiliar para chamadas de função, operações aninhadas e funções adiadas/adiadas.
- Podemos gerenciar chamadas de função usando Stacks.
- As pilhas também são utilizadas para avaliar as expressões aritméticas em diferentes linguagens de programação.
- As pilhas também são úteis na conversão de expressões infixas em expressões pós-fixadas.
- As pilhas nos permitem verificar a sintaxe da expressão no ambiente de programação.
- Podemos combinar parênteses usando Stacks.
- Pilhas podem ser usadas para reverter uma String.
- As pilhas são úteis na resolução de problemas com base no retrocesso.
- Podemos usar Stacks em pesquisa em profundidade no gráfico e na travessia de árvore.
- As pilhas também são usadas em funções do sistema operacional.
- As pilhas também são usadas nas funções UNDO e REDO em uma edição.
4. Caudas
A Fila é uma estrutura de dados linear semelhante a uma pilha com algumas limitações na inserção e exclusão dos elementos. A inserção de um elemento em uma Queue é feita em uma extremidade, e a remoção é feita em outra extremidade ou oposta. Assim, podemos concluir que a estrutura de dados da Fila segue o princípio FIFO (First In, First Out) para manipular os elementos de dados. A implementação de filas pode ser feita usando arrays, listas vinculadas ou pilhas. Alguns exemplos reais de filas são uma fila no balcão de passagens, uma escada rolante, um lava-jato e muito mais.

Figura 7. Um exemplo de fila na vida real
A imagem acima é uma ilustração real de um balcão de ingressos de cinema que pode nos ajudar a entender a fila onde o cliente que chega primeiro é sempre atendido primeiro. O cliente que chegar por último será, sem dúvida, atendido por último. Ambas as extremidades da fila estão abertas e podem executar operações diferentes. Outro exemplo é uma fila de praça de alimentação onde o cliente é inserido pela retaguarda enquanto o cliente é retirado pela frente após prestar o serviço solicitado.
A seguir estão as operações principais da fila:

Figura 8. Fila
Algumas aplicações de filas:
- As filas geralmente são usadas na operação de pesquisa ampla em gráficos.
- As filas também são usadas nas operações do Job Scheduler de sistemas operacionais, como uma fila de buffer de teclado para armazenar as teclas pressionadas pelos usuários e uma fila de buffer de impressão para armazenar os documentos impressos pela impressora.
- As filas são responsáveis pelo agendamento da CPU, agendamento de tarefas e agendamento de disco.
- As filas prioritárias são utilizadas em operações de download de arquivos em um navegador.
- As filas também são usadas para transferir dados entre dispositivos periféricos e a CPU.
- As filas também são responsáveis por tratar interrupções geradas pelas Aplicações de Usuário para a CPU.
Estruturas de dados não lineares
Estruturas de dados não lineares são estruturas de dados em que os elementos de dados não são organizados em ordem sequencial. Aqui, a inserção e remoção de dados não são viáveis de forma linear. Existe um relacionamento hierárquico entre os itens de dados individuais.
Tipos de estruturas de dados não lineares
A seguir está a lista de estruturas de dados não lineares que geralmente usamos:
1. Árvores
Uma árvore é uma estrutura de dados não linear e uma hierarquia contendo uma coleção de nós de forma que cada nó da árvore armazene um valor e uma lista de referências a outros nós (os 'filhos').
A estrutura de dados em árvore é um método especializado para organizar e coletar dados no computador para serem utilizados de forma mais eficaz. Ele contém um nó central, nós estruturais e subnós conectados por meio de arestas. Também podemos dizer que a estrutura de dados em árvore consiste em raízes, galhos e folhas conectadas.

Figura 9. Uma árvore
As árvores podem ser classificadas em diferentes tipos:
Algumas aplicações de árvores:
lista de arrays em java
- As árvores implementam estruturas hierárquicas em sistemas de computador, como diretórios e sistemas de arquivos.
- As árvores também são usadas para implementar a estrutura de navegação de um site.
- Podemos gerar código como o código de Huffman usando Árvores.
- As árvores também são úteis na tomada de decisões em aplicações de jogos.
- As árvores são responsáveis por implementar filas de prioridade para funções de agendamento de sistema operacional baseadas em prioridade.
- As árvores também são responsáveis por analisar expressões e instruções nos compiladores de diferentes linguagens de programação.
- Podemos usar Árvores para armazenar chaves de dados para indexação para Sistema de Gerenciamento de Banco de Dados (SGBD).
- Spanning Trees nos permite encaminhar decisões em redes de computadores e comunicações.
- As árvores também são usadas no algoritmo de localização de caminhos implementado em aplicações de inteligência artificial (IA), robótica e videogames.
2. Gráficos
corda muito longa
Um gráfico é outro exemplo de estrutura de dados não linear que compreende um número finito de nós ou vértices e as arestas que os conectam. Os gráficos são utilizados para resolver problemas do mundo real, nos quais denota a área problemática como uma rede, como redes sociais, redes de circuitos e redes telefônicas. Por exemplo, os nós ou vértices de um grafo podem representar um único usuário em uma rede telefônica, enquanto as arestas representam a ligação entre eles via telefone.
A estrutura de dados do gráfico, G, é considerada uma estrutura matemática composta por um conjunto de vértices, V e um conjunto de arestas, E conforme mostrado abaixo:
G = (V,E)

Figura 10. Um gráfico
A figura acima representa um gráfico com sete vértices A, B, C, D, E, F, G e dez arestas [A, B], [A, C], [B, C], [B, D], [B, E], [C, D], [D, E], [D, F], [E, F] e [E, G].
Dependendo da posição dos vértices e arestas, os gráficos podem ser classificados em diferentes tipos:
Algumas aplicações de gráficos:
- Os gráficos nos ajudam a representar rotas e redes em aplicações de transporte, viagens e comunicação.
- Os gráficos são usados para exibir rotas no GPS.
- Os gráficos também nos ajudam a representar as interconexões em redes sociais e outras aplicações baseadas em redes.
- Os gráficos são utilizados em aplicativos de mapeamento.
- Os gráficos são responsáveis pela representação da preferência do usuário em aplicações de e-commerce.
- Os gráficos também são utilizados em redes de serviços públicos para identificar os problemas colocados às empresas locais ou municipais.
- Os gráficos também ajudam a gerenciar a utilização e disponibilidade de recursos em uma organização.
- Os gráficos também são utilizados para fazer mapas de links de documentos dos sites, a fim de exibir a conectividade entre as páginas por meio de hiperlinks.
- Os gráficos também são usados em movimentos robóticos e redes neurais.
Operações Básicas de Estruturas de Dados
Na seção a seguir, discutiremos os diferentes tipos de operações que podemos realizar para manipular dados em cada estrutura de dados:
- Tempo de compilação
- Tempo de execução
Por exemplo, o Malloc() A função é usada na linguagem C para criar estrutura de dados.
Compreendendo o tipo de dados abstrato
Conforme Instituto Nacional de Padrões e Tecnologia (NIST) , uma estrutura de dados é um arranjo de informações, geralmente na memória, para melhor eficiência do algoritmo. As estruturas de dados incluem listas vinculadas, pilhas, filas, árvores e dicionários. Também poderiam ser uma entidade teórica, como o nome e endereço de uma pessoa.
Da definição mencionada acima, podemos concluir que as operações na estrutura de dados incluem:
- Um alto nível de abstrações, como adição ou exclusão de um item de uma lista.
- Pesquisando e classificando um item em uma lista.
- Acessando o item de maior prioridade em uma lista.
Sempre que a estrutura de dados realiza tais operações, ela é conhecida como Tipo de dados abstrato (ADT) .
Podemos defini-lo como um conjunto de elementos de dados junto com as operações nos dados. O termo 'abstrato' refere-se ao fato de que os dados e as operações fundamentais neles definidos estão sendo estudados independentemente de sua implementação. Inclui o que podemos fazer com os dados, não como podemos fazê-lo.
Uma implementação ADI contém uma estrutura de armazenamento para armazenar os elementos de dados e algoritmos para operação fundamental. Todas as estruturas de dados, como array, lista vinculada, fila, pilha, etc., são exemplos de ADT.
Compreendendo as vantagens de usar ADTs
No mundo real, os programas evoluem como consequência de novas restrições ou requisitos, pelo que a modificação de um programa geralmente requer uma alteração numa ou múltiplas estruturas de dados. Por exemplo, suponha que queiramos inserir um novo campo no registro de um funcionário para acompanhar mais detalhes sobre cada funcionário. Nesse caso, podemos melhorar a eficiência do programa substituindo um Array por uma estrutura Linked. Em tal situação, reescrever todos os procedimentos que utilizam a estrutura modificada é inadequado. Conseqüentemente, uma alternativa melhor é separar uma estrutura de dados de suas informações de implementação. Este é o princípio por trás do uso de tipos de dados abstratos (ADT).
Algumas aplicações de estruturas de dados
A seguir estão algumas aplicações de estruturas de dados:
- Estruturas de dados auxiliam na organização dos dados na memória de um computador.
- As Estruturas de Dados também auxiliam na representação das informações nos bancos de dados.
- Estruturas de dados permitem a implementação de algoritmos para pesquisar dados (por exemplo, mecanismo de pesquisa).
- Podemos usar as Estruturas de Dados para implementar os algoritmos de manipulação de dados (por exemplo, processadores de texto).
- Também podemos implementar algoritmos para analisar dados usando estruturas de dados (por exemplo, mineradores de dados).
- Estruturas de dados suportam algoritmos para gerar os dados (por exemplo, um gerador de números aleatórios).
- As estruturas de dados também oferecem suporte a algoritmos para compactar e descompactar os dados (por exemplo, um utilitário zip).
- Também podemos usar estruturas de dados para implementar algoritmos para criptografar e descriptografar os dados (por exemplo, um sistema de segurança).
- Com a ajuda de estruturas de dados, podemos construir software que possa gerenciar arquivos e diretórios (por exemplo, um gerenciador de arquivos).
- Também podemos desenvolver software que pode renderizar gráficos usando estruturas de dados. (Por exemplo, um navegador da web ou software de renderização 3D).
Além dessas, conforme mencionado anteriormente, existem muitas outras aplicações de Estruturas de Dados que podem nos ajudar a construir qualquer software desejado.