Lemos as estruturas de dados lineares como array, lista vinculada, pilha e fila nas quais todos os elementos são organizados de maneira sequencial. As diferentes estruturas de dados são usadas para diferentes tipos de dados.
Alguns fatores são considerados para a escolha da estrutura de dados:
Uma árvore também é uma das estruturas de dados que representam dados hierárquicos. Suponha que queiramos mostrar os funcionários e seus cargos na forma hierárquica, então isso pode ser representado conforme mostrado abaixo:
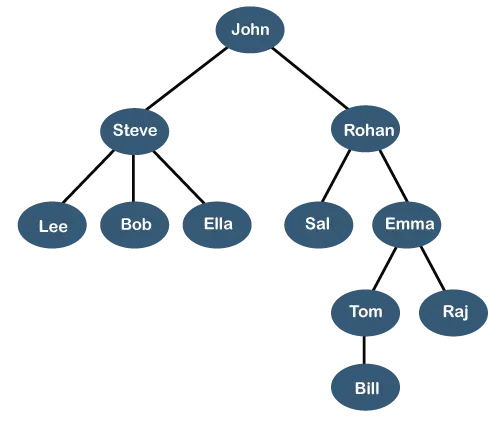
A árvore acima mostra o hierarquia da organização de alguma empresa. Na estrutura acima, John é o CEO da empresa, e John tem dois subordinados diretos nomeados como Steve e Rohan . Steve tem três subordinados diretos chamados Lee, Bob, Ella onde Steve é um gerente. Bob tem dois subordinados diretos chamados Podemos e Ema . Ema tem dois subordinados diretos chamados Tom e Raj . Tom tem um subordinado direto chamado Conta . Esta estrutura lógica específica é conhecida como Árvore . Sua estrutura é semelhante à árvore real, por isso é chamada de Árvore . Nesta estrutura, o raiz está no topo e seus galhos estão se movendo para baixo. Portanto, podemos dizer que a estrutura de dados em Árvore é uma forma eficiente de armazenar os dados de forma hierárquica.
Vamos entender alguns pontos-chave da estrutura de dados em árvore.
- Uma estrutura de dados em árvore é definida como uma coleção de objetos ou entidades conhecidas como nós que são vinculados entre si para representar ou simular hierarquia.
- Uma estrutura de dados em árvore é uma estrutura de dados não linear porque não armazena de maneira sequencial. É uma estrutura hierárquica, pois os elementos de uma árvore são organizados em vários níveis.
- Na estrutura de dados em árvore, o nó superior é conhecido como nó raiz. Cada nó contém alguns dados e os dados podem ser de qualquer tipo. Na estrutura em árvore acima, o nó contém o nome do funcionário, portanto o tipo de dado seria uma string.
- Cada nó contém alguns dados e o link ou referência de outros nós que podem ser chamados de filhos.
Alguns termos básicos usados na estrutura de dados em árvore.
Vamos considerar a estrutura em árvore, mostrada abaixo:

Na estrutura acima, cada nó é rotulado com algum número. Cada seta mostrada na figura acima é conhecida como link entre os dois nós.
Propriedades da estrutura de dados em árvore

Com base nas propriedades da estrutura de dados em árvore, as árvores são classificadas em várias categorias.
Implementação de Árvore
A estrutura de dados em árvore pode ser criada criando os nós dinamicamente com a ajuda de ponteiros. A árvore na memória pode ser representada conforme mostrado abaixo:

A figura acima mostra a representação da estrutura de dados em árvore na memória. Na estrutura acima, o nó contém três campos. O segundo campo armazena os dados; o primeiro campo armazena o endereço do filho esquerdo e o terceiro campo armazena o endereço do filho direito.
Na programação, a estrutura de um nó pode ser definida como:
struct node { int data; struct node *left; struct node *right; } A estrutura acima só pode ser definida para árvores binárias porque a árvore binária pode ter no máximo dois filhos e as árvores genéricas podem ter mais de dois filhos. A estrutura do nó para árvores genéricas seria diferente em comparação com a árvore binária.
Aplicações de árvores
A seguir estão as aplicações das árvores:
Tipos de estrutura de dados em árvore
A seguir estão os tipos de uma estrutura de dados em árvore:

Pode haver n número de subárvores em uma árvore geral. Na árvore geral, as subárvores não são ordenadas porque os nós da subárvore não podem ser ordenados.
Toda árvore não vazia tem uma aresta descendente, e essas arestas estão conectadas aos nós conhecidos como nós filhos . O nó raiz é rotulado com nível 0. Os nós que possuem o mesmo pai são conhecidos como irmãos .

Para saber mais sobre a árvore binária, clique no link abaixo:
https://www.javatpoint.com/binary-tree
Cada nó na subárvore esquerda deve conter um valor menor que o valor do nó raiz, e o valor de cada nó na subárvore direita deve ser maior que o valor do nó raiz.
Um nó pode ser criado com a ajuda de um tipo de dados definido pelo usuário conhecido como estrutura, como mostrado abaixo:
struct node { int data; struct node *left; struct node *right; } Acima está a estrutura do nó com três campos: campo de dados, o segundo campo é o ponteiro esquerdo do tipo de nó e o terceiro campo é o ponteiro direito do tipo de nó.
Para saber mais sobre a árvore de pesquisa binária, clique no link abaixo:
https://www.javatpoint.com/binary-search-tree
É um dos tipos da árvore binária, ou podemos dizer que é uma variante da árvore binária de busca. A árvore AVL satisfaz a propriedade do árvore binária bem como do árvore de pesquisa binária . É uma árvore binária de busca com auto-equilíbrio que foi inventada por Adelson Velsky Lindas . Aqui, autoequilíbrio significa equilibrar as alturas da subárvore esquerda e da subárvore direita. Este equilíbrio é medido em termos de fator de equilíbrio .
Podemos considerar uma árvore como uma árvore AVL se a árvore obedecer à árvore de busca binária, bem como a um fator de equilíbrio. O fator de equilíbrio pode ser definido como o diferença entre a altura da subárvore esquerda e a altura da subárvore direita . O valor do fator de equilíbrio deve ser 0, -1 ou 1; portanto, cada nó na árvore AVL deve ter o valor do fator de balanceamento como 0, -1 ou 1.
Para saber mais sobre a árvore AVL, clique no link abaixo:
https://www.javatpoint.com/avl-tree
A árvore rubro-negra é a árvore de pesquisa binária. O pré-requisito da árvore Rubro-Negra é que saibamos sobre a árvore de pesquisa binária. Em uma árvore de pesquisa binária, o valor da subárvore esquerda deve ser menor que o valor desse nó, e o valor da subárvore direita deve ser maior que o valor desse nó. Como sabemos que a complexidade de tempo da pesquisa binária no caso médio é log2n, o melhor caso é O(1) e o pior caso é O(n).
Quando qualquer operação é realizada na árvore, queremos que nossa árvore seja balanceada para que todas as operações como pesquisa, inserção, exclusão, etc., levem menos tempo, e todas essas operações tenham a complexidade de tempo de registro2n.
A árvore rubro-negra é uma árvore de pesquisa binária com autoequilíbrio. A árvore AVL também é uma árvore de pesquisa binária com balanceamento de altura, então por que exigimos uma árvore rubro-negra . Na árvore AVL não sabemos quantas rotações seriam necessárias para equilibrar a árvore, mas na árvore rubro-negra são necessárias no máximo 2 rotações para equilibrar a árvore. Ele contém um bit extra que representa a cor vermelha ou preta de um nó para garantir o equilíbrio da árvore.
A estrutura de dados da árvore splay também é uma árvore de pesquisa binária na qual o elemento acessado recentemente é colocado na posição raiz da árvore executando algumas operações de rotação. Aqui, espalhando significa o nó acessado recentemente. É um auto-equilíbrio árvore de pesquisa binária sem condição de equilíbrio explícita como AVL árvore.
Pode ser que a altura da árvore splay não esteja equilibrada, ou seja, a altura das subárvores esquerda e direita pode ser diferente, mas as operações na árvore splay tomam a ordem de calma hora em que n é o número de nós.
A árvore Splay é uma árvore balanceada, mas não pode ser considerada uma árvore balanceada em altura porque após cada operação é realizada uma rotação que leva a uma árvore balanceada.
A estrutura de dados Treap veio da estrutura de dados Tree e Heap. Portanto, compreende as propriedades das estruturas de dados Tree e Heap. Na árvore de pesquisa binária, cada nó da subárvore esquerda deve ser igual ou menor que o valor do nó raiz e cada nó da subárvore direita deve ser igual ou maior que o valor do nó raiz. Na estrutura de dados heap, as subárvores direita e esquerda contêm chaves maiores que a raiz; portanto, podemos dizer que o nó raiz contém o valor mais baixo.
Na estrutura de dados treap, cada nó possui ambos chave e prioridade onde a chave é derivada da árvore de pesquisa binária e a prioridade é derivada da estrutura de dados heap.
string substitui tudo java
O Armadilha a estrutura de dados segue duas propriedades que são fornecidas abaixo:
- Filho direito de um nó>=nó atual e filho esquerdo de um nó<=current node (binary tree)< li>
- Os filhos de qualquer subárvore devem ser maiores que o nó (heap)
A árvore B é equilibrada caminho árvore onde eu define a ordem da árvore. Até agora, lemos que o nó contém apenas uma chave, mas a árvore b pode ter mais de uma chave e mais de 2 filhos. Ele sempre mantém os dados classificados. Na árvore binária, é possível que os nós folha possam estar em níveis diferentes, mas na árvore b, todos os nós folha devem estar no mesmo nível.
Se a ordem for m, o nó terá as seguintes propriedades:
- Cada nó em uma árvore b pode ter no máximo eu crianças
- Para o mínimo de filhos, um nó folha tem 0 filhos, o nó raiz tem no mínimo 2 filhos e o nó interno tem teto mínimo de m/2 filhos. Por exemplo, o valor de m é 5, o que significa que um nó pode ter 5 filhos e os nós internos podem conter no máximo 3 filhos.
- Cada nó possui chaves máximas (m-1).
O nó raiz deve conter no mínimo 1 chave e todos os outros nós devem conter pelo menos teto de m/2 menos 1 chaves.